
Qué estudiar para tu entrevista de Desarrollador Java Backend
Posted on July 18, 2023 • 37 minutes • 7770 words • Other languages: English
Una guía de posibles preguntas que puedes encontrarte en tu próxima entrevista.
Introducción
Este es un articulo bastante extenso. Consiste en 25 preguntas que usé como práctica para mi última entrevista.
Obviamente, esto no es garantía de que con este conocimiento vas a conseguir tu trabajo ideal. Pero al menos a mi, programador argentino sin título universitario con año y medio de experiencia laboral, me sirvió para encontrar un trabajo en dólares.
(AFIP si estás leyendo esto, mi sueldo ecuatoriano va a parar a una cuenta británica, asi que no tienes poder acá, gg)
Java en general
1. En Java, ¿cuál es la diferencia entre una interfaz y una clase abstracta?
En Java, una interfaz es una colección de métodos abstractos que definen un conjunto de comportamientos o capacidades que una clase puede implementar. Una clase abstracta, por otro lado, es una clase que no se puede instanciar y puede contener métodos abstractos y no abstractos.
Estas son algunas de las diferencias clave entre las interfaces y las clases abstractas:
| Clase abstracta | Interfaz |
|---|---|
| Tiene tanto métodos concretos como métodos abstactos | Solo puede tener métodos abstractos |
| Solo puede extender de una única clase abstracta | Puede implementar cualquier cantidad de interfaces |
| Puede tener un método constructor | No puede tener un método constructor |
| Los atributos pueden tener cualquier visibilidad | Los atributos pueden ser unicamente públicos |
| Puede tener variables de instancia | No puede tener variable de instancia |
En resumen, las interfaces se utilizan para definir un conjunto de comportamientos que debe implementar una clase, mientras que las clases abstractas proporcionan una implementación y un comportamiento comunes que sus subclases pueden heredar.
2. Con tus propias palabras, ¿podrías describir qué es una interfaz?
Una interfaz en Java es un modelo para un conjunto de métodos relacionados que definen un contrato o un conjunto de comportamientos que debe implementar una clase. Proporciona una forma para que diferentes objetos se comuniquen entre sí sin conocer sus detalles de implementación específicos.
Una interfaz se define mediante la palabra clave interface y solo contiene firmas de métodos (es decir, el nombre del método, los parámetros y el tipo de devolución), pero no contiene detalles de implementación. Una clase que implementa una interfaz debe proporcionar una implementación para todos los métodos definidos en la interfaz.
Las interfaces son útiles en situaciones en las que necesitamos definir un conjunto común de comportamientos que diferentes clases pueden implementar a su manera. Por ejemplo, la interfaz Comparable en Java define un método compareTo() que puede ser implementado por cualquier clase que quiera ser comparable con otros objetos. Esto nos permite ordenar objetos de diferentes clases usando el mismo algoritmo.
En general, las interfaces brindan un mecanismo poderoso para la abstracción y el desacoplamiento en los programas de Java, y juegan un papel clave en la definición de las API y el diseño de sistemas de software que son flexibles, extensibles y mantenibles.
3. ¿Cuándo es útil un método estático?
Un método estático es un método que pertenece a una clase en lugar de una instancia de esa clase. Los métodos estáticos se pueden llamar en la propia clase sin crear una instancia de la clase. Aquí hay algunas situaciones en las que los métodos estáticos pueden ser útiles:
-
Métodos de utilidad: los métodos estáticos se pueden usar para definir métodos de utilidad que realizan operaciones comunes que no requieren una instancia de la clase. Por ejemplo, la clase
Mathen Java tiene varios métodos estáticos comoMath.max()yMath.min()que se usan con frecuencia en cálculos matemáticos. -
Métodos de fábrica: los métodos estáticos se pueden usar para definir métodos de fábrica que crean instancias de la clase. Por ejemplo, el método
getInstance()en el patrón de diseñoSingletones un método estático que devuelve la única instancia de la clase. -
Métodos auxiliares: los métodos estáticos se pueden utilizar para definir métodos auxiliares que utilizan otros métodos de la clase. Por ejemplo, se podría usar un método estático para validar los parámetros de entrada de un método no estático en la misma clase.
-
Optimización del rendimiento: los métodos estáticos pueden mejorar el rendimiento al reducir la creación de objetos y la sobrecarga de recolección de elementos no utilizados. Dado que los métodos estáticos no requieren que se cree una instancia de la clase, pueden ser más eficientes cuando se los llama con frecuencia.
-
Simplicidad y legibilidad: los métodos estáticos pueden hacer que el código sea más simple y legible al evitar la necesidad de crear una instancia de la clase. Esto puede ser particularmente útil para operaciones simples sin estado.
Sin embargo, es importante usar métodos estáticos con prudencia y solo cuando sea apropiado. El uso excesivo de métodos estáticos puede hacer que el código sea más difícil de probar y mantener, y puede conducir a un código estrechamente acoplado y difícil de cambiar.
Java 8
4. ¿Qué mejoras sustanciales se introdujeron en Java 8?
Java 8 introdujo varias mejoras significativas en el lenguaje y la plataforma Java. Estos son algunos de los más importantes:
-
Lambdas: Java 8 introdujo soporte para expresiones lambda, que son una nueva forma de escribir código funcional y conciso. Las Lambdas facilitan la escritura de código que es más expresivo y más fácil de leer, especialmente para operaciones como el filtrado, el mapeo y la reducción de colecciones.
-
Stream API: Java 8 también presentó Stream API, que proporciona una forma poderosa y flexible de procesar colecciones de datos. La API de Stream funciona a la perfección con expresiones lambda y facilita la escritura de código que sea conciso y expresivo.
-
Métodos predeterminados en las interfaces: Java 8 permite que las interfaces tengan métodos predeterminados, lo que proporciona una forma de agregar nuevas funciones a una interfaz sin interrumpir las implementaciones existentes. Esto facilita la evolución de las interfaces con el tiempo sin introducir problemas de compatibilidad con versiones anteriores.
-
API de fecha y hora: Java 8 introdujo una nueva API de fecha y hora que brinda una forma más flexible y poderosa de trabajar con fechas y horas. La nueva API facilita la realización de operaciones comunes como calcular la diferencia entre dos fechas o formatear una fecha para su visualización.
-
Clase opcional: Java 8 introdujo la clase opcional, que proporciona una forma de manejar valores nulos de una manera más expresiva y concisa. La clase Opcional deja en claro cuándo un valor puede estar ausente y obliga a los desarrolladores a manejar ese caso explícitamente.
-
Motor Nashorn JavaScript: Java 8 también introdujo el motor Nashorn JavaScript, que proporciona una forma de ejecutar código JavaScript dentro de una aplicación Java. Esto facilita la integración del código JavaScript en las aplicaciones Java y proporciona una forma más consistente de manejar las tareas de secuencias de comandos.
En general, Java 8 introdujo varias mejoras importantes en el lenguaje y la plataforma Java, lo que facilita la escritura de código expresivo, funcional y fácil de mantener.
5. Explique algunos conceptos de programación funcional: API Streams, referencia de métodos, funciones como ciudadanos de primera clase, funciones anónimas (expresiones lambda)
API Streams
La API Streams es una de las principales características introducidas en Java 8, que proporciona un enfoque de programación funcional para procesar colecciones de objetos. Permite a los desarrolladores realizar operaciones como filtrado, clasificación y mapeo en una colección de una manera más concisa y eficiente.
Los flujos se componen de tres componentes principales:
- Fuente: una colección de objetos o una matriz.
- Operaciones intermedias: Operaciones que transforman el flujo en otro flujo. Los ejemplos incluyen filter(), map() y sorted().
- Operaciones terminales: Operaciones que producen un resultado o un efecto secundario. Los ejemplos incluyen forEach(), count() y reduce().
Este es un ejemplo del uso de la API Streams para filtrar una lista de nombres que comienzan con la letra “A” e imprimirlos:
List<String> names = Arrays.asList("Alice", "Bob", "Amy", "John");
names
.stream()
.filter(name -> name.startsWith("A"))
.forEach(System.out::println);
Este código generará:
Alice
Amy
Este es solo un ejemplo simple, pero la API de Streams se puede usar para operaciones mucho más complejas en colecciones, como agrupar, unir y agregar datos.
La API de Streams tiene muchas ventajas, como una mejor legibilidad, modularidad y paralelización. Al usar la API de Streams, los desarrolladores pueden escribir un código más conciso y expresivo que es más fácil de leer y mantener.
Referencia de método
La referencia de método es una sintaxis abreviada que le permite referirse a un método existente por su nombre en lugar de escribir una expresión lambda que llame al método. Por ejemplo:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// Using lambda expression
numbers.stream().forEach(n -> System.out.println(n));
// Using method reference
numbers.stream().forEach(System.out::println);
Funciones como ciudadanos de primera clase
Las funciones como ciudadanos de primera clase se refieren a la capacidad de tratar las funciones como valores que otras funciones pueden pasar y devolver. En Java, esto se logra mediante el uso de interfaces funcionales como java.util.function.Function y java.util.function.Predicate. Por ejemplo:
Function<String, Integer> stringLength = String::length;
int length = stringLength.apply("hola"); // length will be 5
Expresiones lambda
Las expresiones lambda son funciones anónimas que se pueden usar como valores, al igual que las funciones normales. A menudo se utilizan con interfaces funcionales para proporcionar una forma más concisa de escribir código. Por ejemplo:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
// Using anonymous function
numbers.stream().filter(n -> n % 2 == 0).forEach(System.out::println);
// Using lambda expression
numbers.stream().filter((Integer n) -> { return n % 2 == 0; }).forEach(System.out::println);
En general, estos conceptos de programación funcional ayudan a que el código Java sea más conciso, expresivo y modular. También pueden facilitar la escritura de código que sea más fácil de mantener y escalable.
Spring Boot
6. ¿Qué es Spring Boot?
![]()
Spring Boot es un marco de código abierto basado en Java que facilita la creación de aplicaciones basadas en Spring de grado de producción que se pueden implementar y ejecutar sin requerir un proceso de configuración complejo.
Spring Boot proporciona un conjunto de plantillas y opiniones preconfiguradas que permiten a los desarrolladores crear, probar e implementar rápidamente sus aplicaciones con una configuración mínima. Simplifica la configuración de aplicaciones basadas en Spring al proporcionar valores predeterminados sensibles y configuración automática de bibliotecas de uso común, lo que reduce la necesidad de configuración manual.
Algunas de las características clave de Spring Boot incluyen:
-
Compatibilidad con servidor integrado: Spring Boot incluye un servidor Tomcat, Jetty o Undertow integrado que se puede utilizar para ejecutar la aplicación sin necesidad de instalar un servidor web por separado.
-
Configuración automática: Spring Boot configura automáticamente la aplicación en función de las bibliotecas que están disponibles en el classpath, lo que reduce la necesidad de una configuración manual.
-
Dependencias de inicio: Spring Boot proporciona un conjunto de dependencias de inicio que simplifican la configuración de bibliotecas comunes como Spring Data, Spring MVC y Spring Security.
-
Actuator: Spring Boot Actuator proporciona un conjunto de funciones listas para producción, como controles de estado, métricas y monitoreo, que se pueden agregar fácilmente a la aplicación.
En general, Spring Boot es un marco poderoso que simplifica el desarrollo de aplicaciones basadas en Spring al reducir la cantidad de código repetitivo y la configuración que se requiere. Ha obtenido una adopción generalizada entre los desarrolladores de Java debido a su facilidad de uso, flexibilidad y soporte de la comunidad.
7. ¿Para qué se utilizan las siguientes anotaciones? @RestController @Service @Repository ¿Puedes nombrar otros además de estos?
@RestController: esta anotación se usa para indicar que una clase es un controlador de servicio web RESTful, lo que significa que maneja las solicitudes HTTP entrantes y produce respuestas HTTP en un formato como JSON o XML. Los métodos en una clase@RestControllergeneralmente se anotan con anotaciones de métodos HTTP como@GetMapping,@PostMapping,@PutMappingo@DeleteMapping.
@RestController
@RequestMapping("/api")
public class ExampleController {
@Autowired
private ExampleService exampleService;
@GetMapping("/example")
public String getExample() {
return exampleService.getExampleData();
}
@PostMapping("/example")
public void createExample(@RequestBody String data) {
exampleService.createExampleData(data);
}
@PutMapping("/example/{id}")
public void updateExample(@PathVariable String id, @RequestBody String data) {
exampleService.updateExampleData(id, data);
}
@DeleteMapping("/example/{id}")
public void deleteExample(@PathVariable String id) {
exampleService.deleteExampleData(id);
}
}
@Service: esta anotación se usa para indicar que una clase es un componente de servicio en una aplicación Spring, lo que significa que contiene lógica de negocios que pueden usar varias partes de la aplicación. Una clase@Servicegeneralmente interactúa con repositorios u otros componentes de acceso a datos para realizar operaciones CRUD (crear, leer, actualizar, eliminar) en objetos de dominio.
@Service
public class ExampleService {
@Autowired
private ExampleRepository exampleRepository;
public Example getObjectById(Long id) {
return exampleRepository.findById(id);
}
public void createObject(Example object) {
exampleRepository.save(object);
}
public void updateObject(Example object) {
exampleRepository.save(object);
}
public void deleteObject(Long id) {
exampleRepository.deleteById(id);
}
}
@Repository: esta anotación se usa para indicar que una clase es un componente de repositorio en una aplicación Spring, lo que significa que proporciona acceso a una fuente de datos como una base de datos, un sistema de archivos o una API externa. Una clase@Repositorygeneralmente contiene métodos para leer, escribir y consultar datos de la fuente de datos.
@Repository
public class ExampleRepository {
public void saveData(String data) {
// save logic
}
public String fetchData() {
// fetch logic
return "Example Data";
}
public void deleteData() {
// delete logic
}
}
Otras anotaciones de uso común en las aplicaciones Spring incluyen:
-
@Autowired: esta anotación se utiliza para inyectar dependencias en un bean gestionado por Spring. Se puede usar en parámetros, campos o métodos del constructor. -
@Configuration: esta anotación se usa para indicar que una clase es un componente de configuración en una aplicación Spring, lo que significa que contiene opciones de configuración y definiciones de beans que se usan para configurar el contexto de la aplicación. -
@Component: esta anotación se usa para indicar que una clase es un bean genérico administrado por Spring. A menudo se usa como una anotación general para las clases que no encajan en una de las categorías de anotaciones más específicas. -
@PathVariable: esta anotación se usa para indicar que un parámetro de método debe completarse con un valor de una variable de ruta de URL. -
@RequestBody: esta anotación se usa para indicar que un parámetro de método debe completarse con el cuerpo de la solicitud de una solicitud HTTP entrante.
Hay muchas otras anotaciones proporcionadas por Spring y sus extensiones, y cada una tiene un propósito específico en la creación de aplicaciones Spring.
8. Explique las anotaciones de Java más utilizadas para el modelado de datos con Hibernate y la serialización de datos con Jackson
- @Entity: se utiliza para anotar una clase Java que es una entidad en una tabla de base de datos.
- @Id: se utiliza para especificar la clave principal de una entidad.
- @GeneratedValue: se utiliza para especificar la estrategia de generación de los valores de las claves primarias.
- @Column: se utiliza para especificar la asignación entre un campo de clase Java y una columna de base de datos.
@Entity
@Table(name = "example_table")
public class ExampleEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "id")
private Long id;
@Column(name = "name")
private String name;
@Column(name = "age")
private int age;
// Constructor, getters and setters
}
Algunas anotaciones populares de Java utilizadas para la serialización de datos con Jackson son:
- @JsonFormat: se utiliza para especificar el formato de un campo de fecha u hora.
- @JsonProperty: se utiliza para especificar el nombre de una propiedad en la salida JSON.
- @JsonIgnore: se utiliza para ignorar una propiedad durante la serialización y deserialización de JSON.
- @JsonInclude: se utiliza para especificar cuándo se debe incluir una propiedad en la salida JSON, en función de su valor.
public class ExampleData {
@JsonFormat(pattern = "yyyy-MM-dd")
private Date dateOfBirth;
@JsonProperty("full_name")
private String fullName;
@JsonIgnore
private String password;
@JsonInclude(JsonInclude.Include.NON_NULL)
private String address;
// Getters and setters
}
9. ¿Qué es la anotación @Slf4j? ¿Por qué es útil?
La anotación @Slf4j es una anotación de Lombok que se puede usar para generar automáticamente código de registro en una clase Java. La anotación normalmente se coloca en el nivel de clase, justo encima de la declaración de clase.
Cuando se utiliza la anotación @Slf4j, Lombok genera un campo final estático privado denominado log en la clase, que se inicializa en una instancia de registrador mediante la API de Simple Logging Facade para Java (SLF4J). El registrador generado se puede utilizar para registrar mensajes en diferentes niveles de gravedad (p. ej., depuración, información, advertencia, error) mediante los métodos proporcionados por la API de SLF4J.
Por ejemplo, el siguiente código demuestra cómo usar la anotación @Slf4j para generar un registrador en una clase Java
@Slf4j
public class MyClass {
public void doSomething() {
log.info("Doing something...");
// ...
}
}
En este ejemplo, Lombok genera el siguiente código para la clase MyClass:
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class MyClass {
private static final Logger log = LoggerFactory.getLogger(MyClass.class);
public void doSomething() {
log.info("Doing something...");
// ...
}
}
La anotación @Slf4j es útil porque permite a los desarrolladores agregar fácilmente código de registro a sus clases sin tener que escribir código repetitivo. También garantiza que la instancia del registrador se inicialice correctamente y proporciona una interfaz de registro uniforme y estándar en todo el código base. Además, el uso de un marco de registro como SLF4J puede mejorar el rendimiento del código de registro al evitar la concatenación de cadenas innecesaria al crear mensajes de registro.
10. ¿Qué ventajas puede mencionar de usar spring-webflux?
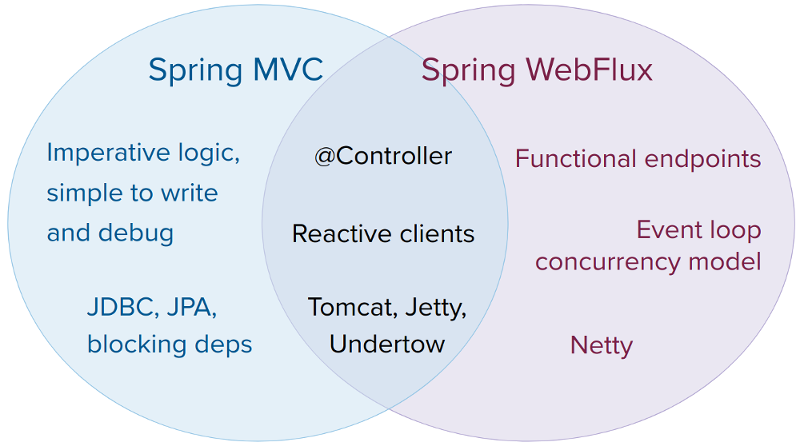
-
Modelo de programación reactiva: Spring WebFlux está diseñado con un modelo de programación reactiva que le permite crear aplicaciones con mayor capacidad de respuesta y resistencia. La programación reactiva es un paradigma de programación que le permite crear aplicaciones que pueden reaccionar a eventos y manejar grandes cantidades de solicitudes simultáneas con una sobrecarga mínima.
-
Alta escalabilidad: Spring WebFlux se basa en la biblioteca Reactor, que proporciona un poderoso conjunto de herramientas para crear aplicaciones reactivas. Estas herramientas hacen posible manejar altos niveles de simultaneidad y escalar hacia arriba y hacia abajo fácilmente a medida que cambia la demanda.
-
E/S sin bloqueo: Spring WebFlux utiliza E/S sin bloqueo, lo que significa que puede manejar muchas solicitudes sin bloquear subprocesos. Esto hace posible crear aplicaciones que respondan mejor y puedan manejar más tráfico sin aumentar los requisitos de hardware.
-
Huella ligera: Spring WebFlux tiene una huella ligera, lo que significa que se puede implementar en entornos con recursos limitados. Esto lo hace ideal para crear microservicios y aplicaciones nativas de la nube que deben implementarse en una variedad de plataformas.
-
Integración con otros módulos Spring: Spring WebFlux es parte del ecosistema Spring más grande, lo que significa que se integra a la perfección con otros módulos Spring, como Spring Boot, Spring Data y Spring Security. Esto facilita la creación de aplicaciones de un extremo a otro utilizando Spring.
-
Compatibilidad con múltiples protocolos: Spring WebFlux admite múltiples protocolos, como HTTP, WebSocket y TCP. Esto hace posible crear aplicaciones que pueden manejar una variedad de flujos de datos y patrones de comunicación.
En general, Spring WebFlux es una herramienta poderosa para crear aplicaciones reactivas, escalables y con capacidad de respuesta. Ofrece una serie de ventajas sobre los marcos de E/S de bloqueo tradicionales y es ideal para crear microservicios y aplicaciones nativas de la nube.
11. ¿Qué es gradle?

Gradle es una herramienta de automatización de compilación de código abierto que se utiliza para automatizar el proceso de creación, prueba e implementación de proyectos de software. Está diseñado para ser altamente personalizable y flexible, lo que lo hace ideal para una amplia gama de proyectos y flujos de trabajo de desarrollo.
Gradle utiliza un lenguaje específico de dominio (DSL) basado en Groovy para definir los scripts de compilación que automatizan las diversas tareas involucradas en el proceso de compilación. Estas tareas pueden incluir la compilación del código fuente, la ejecución de pruebas, la generación de documentación y el empaquetado de la aplicación final.
Gradle es conocido por sus potentes capacidades de gestión de dependencias, que facilitan la gestión de dependencias de proyectos complejos y garantizan que todas las bibliotecas y marcos necesarios estén disponibles para el proyecto.
Gradle también tiene una comunidad grande y activa de desarrolladores, que han contribuido con muchos complementos y extensiones que se pueden usar para ampliar la funcionalidad de la herramienta. Esto significa que es fácil encontrar complementos para una amplia gama de tareas, como análisis de calidad de código, informes de cobertura de código e implementación en plataformas en la nube.
Muchas empresas y organizaciones utilizan Gradle para automatizar sus procesos de desarrollo de software, incluidos Google, Netflix, LinkedIn y Airbnb, entre otros. Su popularidad ha crecido rápidamente en los últimos años y ahora es una de las herramientas de automatización de compilación más utilizadas en el ecosistema de Java.
Arquitectura
12. ¿Cuál es la diferencia entre un servicio monolítico y un microservicio?
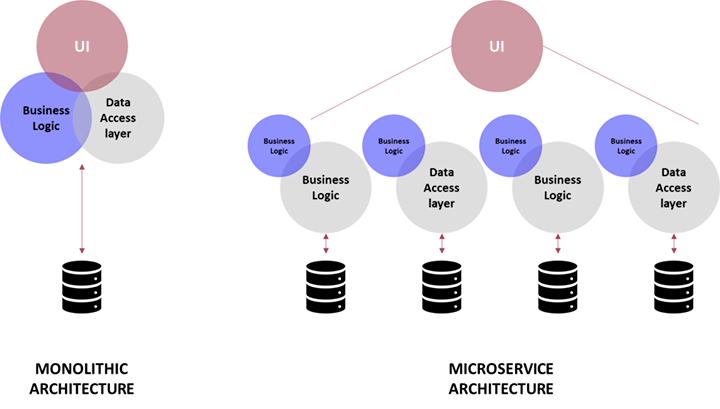
Un servicio monolítico es una arquitectura de software en la que todos los componentes de una aplicación están estrechamente acoplados y se implementan juntos como una sola unidad. En un servicio monolítico, el código de la aplicación se organiza en uno o más módulos, pero todos los módulos comparten el mismo proceso y se ejecutan en un solo entorno de tiempo de ejecución.
Por otro lado, una arquitectura de microservicios es un enfoque en el que una aplicación se construye como una colección de pequeños servicios independientes que están débilmente acoplados y se comunican entre sí a través de una red. En una arquitectura de microservicios, cada servicio es responsable de una capacidad comercial específica y se puede desarrollar, implementar y escalar independientemente de los otros servicios.
La principal diferencia entre una arquitectura monolítica y una de microservicio es la forma en que se organiza y se implementa la aplicación. Los monolitos suelen ser más fáciles de desarrollar e implementar inicialmente, ya que requieren menos configuración e infraestructura. Sin embargo, a medida que la aplicación crece en tamaño y complejidad, se vuelve más difícil de mantener y escalar, ya que cualquier cambio en una parte de la aplicación puede afectar potencialmente a todo el sistema.
Por el contrario, los microservicios ofrecen una mayor flexibilidad y escalabilidad, ya que están diseñados para acoplarse libremente y desplegarse de forma independiente. Cada microservicio puede ser desarrollado y mantenido por un equipo independiente, lo que permite una mayor agilidad y un tiempo de comercialización más rápido. Sin embargo, los microservicios pueden ser más complejos de desarrollar y administrar, ya que requieren más infraestructura y herramientas para manejar la naturaleza distribuida de la arquitectura.
En general, la elección entre una arquitectura monolítica y una de microservicio depende de las necesidades específicas de la aplicación y de la organización que la desarrolla. Ambas arquitecturas tienen sus ventajas y desventajas, y la decisión debe basarse en factores como la escalabilidad, la mantenibilidad, la agilidad y las habilidades y recursos disponibles para el equipo de desarrollo.
13. ¿Cuál es el propósito de BDD?
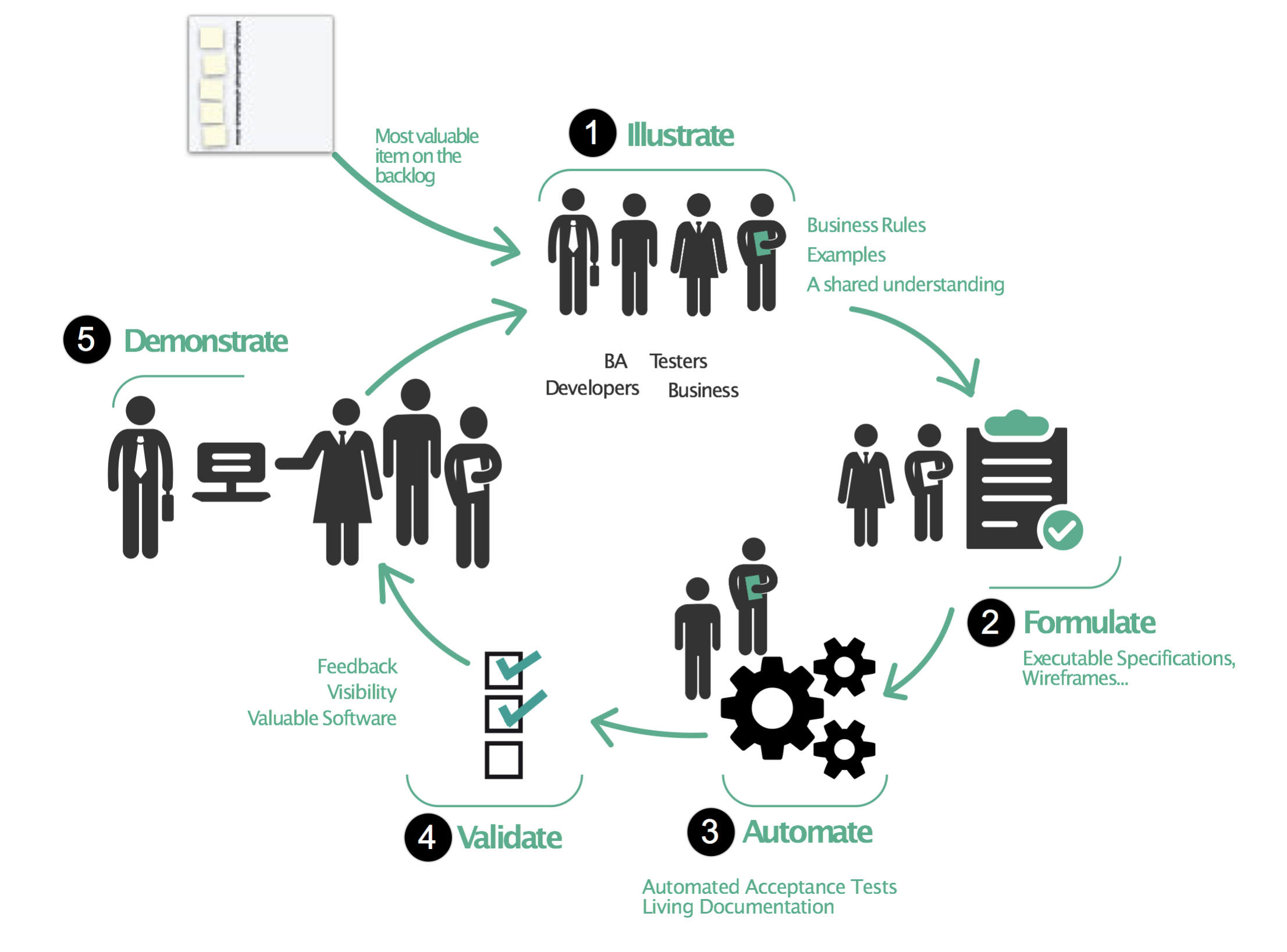
El propósito del Desarrollo Impulsado por el Comportamiento (BDD) es proporcionar un marco y una metodología para desarrollar software que se centre en brindar valor comercial alineando el proceso de desarrollo con el comportamiento deseado del sistema.
BDD tiene como objetivo mejorar la colaboración entre desarrolladores, evaluadores y partes interesadas comerciales al proporcionar un lenguaje y un marco comunes para describir y comprender el comportamiento del sistema. BDD alienta a las partes interesadas a definir el comportamiento deseado del sistema utilizando lenguaje natural, que puede ser entendido por todas las partes involucradas en el proceso de desarrollo.
BDD también enfatiza la importancia de automatizar el proceso de prueba, utilizando herramientas como Cucumber o JBehave para traducir las descripciones del lenguaje natural del comportamiento deseado en pruebas ejecutables. Esto ayuda a garantizar que el código que se está desarrollando esté alineado con el comportamiento deseado del sistema y que los cambios en el código no introduzcan regresiones sin darse cuenta ni rompan la funcionalidad existente.
Al centrarse en el comportamiento del sistema e involucrar a todas las partes interesadas en el proceso de desarrollo, BDD puede ayudar a garantizar que el software que se está desarrollando brinde el valor comercial deseado y satisfaga las necesidades de los usuarios. También promueve la colaboración, la comunicación y una comprensión compartida de los objetivos del proyecto.
Bases de datos
14. ¿Qué tipo de base de datos es redis?

Redis es una base de datos de clave-valor en memoria que se puede usar como caché, intermediario de mensajes o almacén de datos. Está diseñado para ser rápido, escalable y confiable, y a menudo se usa para admitir aplicaciones en tiempo real, como aplicaciones de chat, aplicaciones de juegos y plataformas de comercio financiero.
Redis es una base de datos NoSQL, lo que significa que no utiliza un modelo de base de datos relacional tradicional. En su lugar, utiliza un modelo clave-valor simple, donde cada valor en la base de datos está asociado con una clave única. Redis admite una amplia gama de estructuras de datos, incluidas cadenas, hashes, listas, conjuntos y conjuntos ordenados, lo que la convierte en una base de datos flexible y versátil que se puede utilizar para una amplia gama de aplicaciones.
Una de las características clave de Redis es su almacenamiento de datos en memoria, que le permite ofrecer un rendimiento de lectura y escritura rápido. Redis también incluye soporte integrado para replicación y agrupación, lo que le permite escalar horizontalmente para manejar grandes cantidades de datos y tráfico.
En general, Redis es una base de datos poderosa y flexible que se puede usar para una amplia gama de aplicaciones, y su velocidad y escalabilidad la convierten en una opción popular para aplicaciones en tiempo real y de alto tráfico.
15. De acuerdo con la teoría RDBMS (MySQL, PostgreSQL, MSSQL, Oracle), ¿qué es una Vista y cómo se usa?
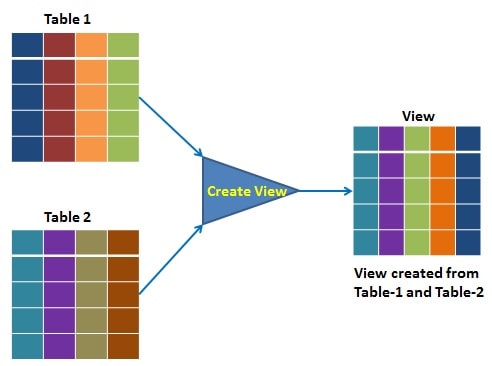
En los sistemas de administración de bases de datos relacionales (RDBMS) como MySQL, PostgreSQL, MSSQL y Oracle, una vista es una tabla virtual que se deriva de una o más tablas o vistas existentes en la base de datos. Una vista no contiene ningún dato propio, sino que es una instrucción SELECT guardada que se ejecuta cada vez que se consulta la vista.
Las vistas se utilizan para simplificar consultas complejas, proporcionar un nivel adicional de seguridad y mejorar el rendimiento al permitir que las consultas utilizadas con frecuencia se guarden y reutilicen. Estos son algunos casos de uso comunes para las vistas:
-
Simplifique las consultas complejas: si una consulta requiere varias uniones, cálculos complejos u otras operaciones complicadas, puede ser difícil escribirla y mantenerla. Se puede crear una vista para simplificar la consulta y hacerla más fácil de entender y trabajar con ella.
-
Mejore el rendimiento: si una consulta se ejecuta con frecuencia, puede ser beneficioso crear una vista para almacenar en caché los resultados. Esto puede mejorar el rendimiento al reducir la cantidad de tiempo necesario para ejecutar la consulta cada vez que se ejecuta.
-
Proporcione un nivel adicional de seguridad: las vistas se pueden usar para restringir el acceso a datos confidenciales al exponer solo un subconjunto de las tablas subyacentes. Por ejemplo, se podría crear una vista para permitir a los usuarios ver la información del cliente sin exponer datos financieros confidenciales.
-
Proporcione una interfaz coherente: si varias aplicaciones o usuarios necesitan acceder a los mismos datos, una vista puede proporcionar una interfaz coherente que abstraiga la complejidad subyacente del esquema de la base de datos.
Para crear una vista en una base de datos relacional, usaría la instrucción CREATE VIEW seguida de una instrucción SELECT que define la vista. Una vez que se ha creado una vista, se puede consultar como cualquier otra tabla en la base de datos. Cualquier cambio realizado en las tablas o vistas subyacentes se reflejará en la vista cuando se consulte.
-- Create view
CREATE VIEW example_view AS
SELECT column1, column2
FROM table1
WHERE condition;
-- Query the view
SELECT * FROM example_view;
16. ¿Cuál es la principal diferencia entre un RDBMS y bases de datos NoSQL (Redis, MongoDB)?
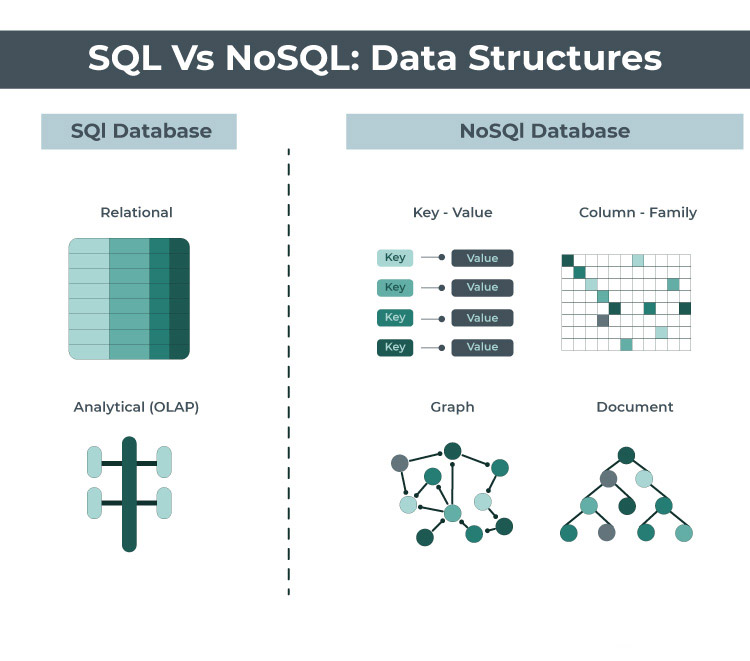
La principal diferencia entre un Sistema de gestión de bases de datos relacionales (RDBMS) y una base de datos NoSQL como Redis o MongoDB es la forma en que se almacenan y se accede a los datos.
RDBMS se basa en el modelo relacional, donde los datos se organizan en tablas, y cada tabla consta de un conjunto de filas y columnas. RDBMS utiliza SQL (lenguaje de consulta estructurado) para manipular y consultar datos. RDBMS es ideal para almacenar datos estructurados que requieren relaciones complejas entre entidades. Los ejemplos de RDBMS incluyen MySQL, PostgreSQL, Oracle y Microsoft SQL Server.
Las bases de datos NoSQL, por otro lado, no se basan en un esquema fijo y permiten modelos de datos más flexibles. Las bases de datos NoSQL están diseñadas para manejar grandes cantidades de datos no estructurados y semiestructurados, lo que las hace ideales para aplicaciones de big data. Las bases de datos NoSQL no utilizan SQL para consultar datos y, en su lugar, utilizan API o lenguajes de consulta patentados. Los ejemplos de bases de datos NoSQL incluyen MongoDB, Redis, Cassandra y Amazon DynamoDB.
| Característica | SQL | NoSQL |
|---|---|---|
| Foco principal | Integridad de los datos | Escalar y adaptarse rápidamente frente al cambio |
| Modelo de datos | Tablas siguiendo un esquema fijo | Esquema flexible: JSON, pares clave-valor, tablas con esquema dinámico, grafos con vértices y aristas |
| Lenguaje de consulta | SQL | Lenguajes de consultas propios / apis |
| Escalabilidad | Vertical: escala con un servidor mas grande | Horizontal: escala a través de varios servidores |
17. ¿Qué es H2?
H2 es una base de datos en memoria de código abierto escrita en Java. Es un sistema de administración de bases de datos relacionales que proporciona una alternativa pequeña, rápida y liviana a los sistemas de bases de datos tradicionales como MySQL, Oracle o PostgreSQL. H2 es compatible con las API de SQL y JDBC, y se puede usar como una base de datos independiente o integrada en aplicaciones Java.
Una de las ventajas de H2 es que se puede ejecutar en memoria, lo que significa que los datos se almacenan en la memoria principal de la computadora en lugar de en el disco. Esto lo hace muy rápido para las operaciones de lectura y escritura, pero también significa que los datos no se conservan cuando se cierra la aplicación. Sin embargo, H2 también es compatible con el almacenamiento basado en disco y se puede configurar para conservar los datos en el disco.
H2 se usa a menudo para pruebas y creación de prototipos, así como para aplicaciones pequeñas y medianas que no requieren un gran sistema de base de datos de nivel empresarial. Se puede integrar con marcos populares como Spring e Hibernate, y admite una variedad de tipos de datos, incluidos JSON, XML y datos espaciales.
En general, H2 es un sistema de base de datos liviano, rápido y fácil de usar que brinda una alternativa útil a los sistemas de administración de bases de datos relacionales tradicionales.
Testing
18. ¿Qué diferencias hay entre las pruebas unitarias y las pruebas de integración?
Pruebas unitarias:
Las pruebas unitarias están diseñadas para probar unidades individuales de código, como métodos o funciones, de forma aislada del resto del sistema. Por lo general, los escriben los desarrolladores y se enfocan en garantizar que las unidades individuales de código se comporten correctamente y produzcan el resultado esperado dada una entrada específica. Las pruebas unitarias suelen tener un alcance pequeño y se ejecutan rápidamente.
En Java, las pruebas unitarias generalmente se implementan utilizando un marco de prueba, como JUnit o TestNG. A menudo usan marcos de simulación, como Mockito, para simular dependencias y aislar el código bajo prueba.
Pruebas de integración:
Las pruebas de integración están diseñadas para probar las interacciones entre diferentes componentes o servicios en un sistema. Por lo general, los escriben evaluadores o ingenieros de control de calidad y se enfocan en garantizar que el sistema en su conjunto se comporte correctamente y produzca el resultado esperado en respuesta a un conjunto específico de entradas.
En Java, las pruebas de integración generalmente se implementan utilizando un marco de prueba, como JUnit o TestNG, y a menudo usan herramientas como Selenium para probar aplicaciones web. Las pruebas de integración pueden requerir más instalación y configuración que las pruebas unitarias y pueden tardar más en ejecutarse.
| Característica | Pruebas unitarias | Pruebas de integración |
|---|---|---|
| Alcance | Unidades individuales de código | Interacciones entre diferentes componentes del sistema |
| Autoría | Desarrollador | Control de calidad |
| Tiempo de ejecución | Rapidas debido a su alcance pequeño | Toman tiempo debido a configuración y gran alcance |
19. ¿Qué es TDD?
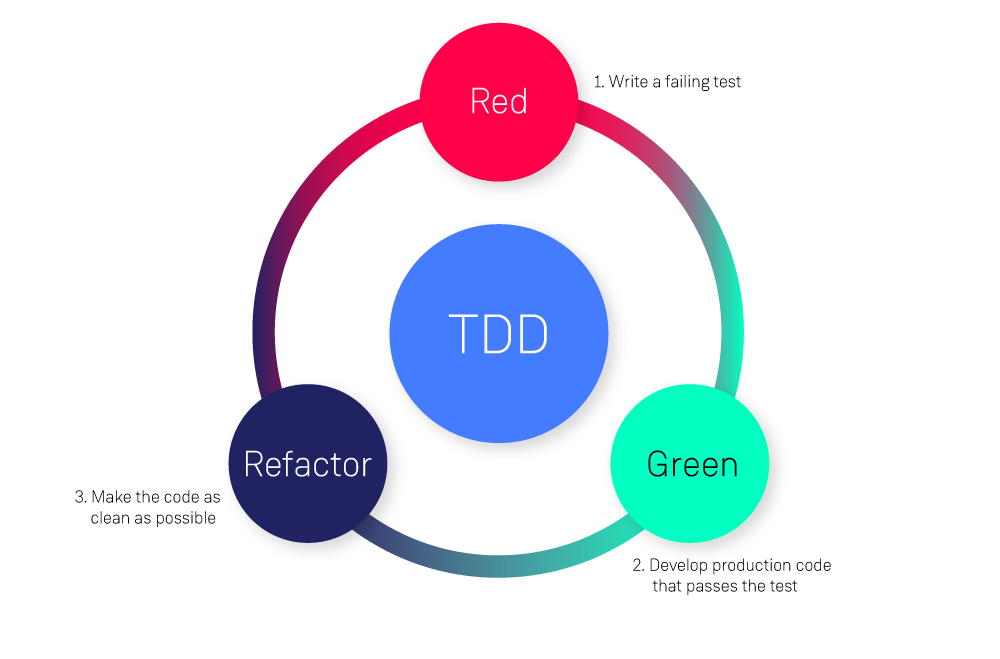
TDD (Test-Driven Development) es una metodología de desarrollo de software en la que los desarrolladores escriben pruebas automatizadas para una función antes de escribir el código real que implementa esa funcionalidad. El proceso TDD normalmente implica tres pasos:
-
Escriba una prueba fallida: el desarrollador escribe una prueba que describe el comportamiento deseado del código, pero falla porque el código aún no existe.
-
Escriba el código: el desarrollador luego escribe la cantidad mínima de código necesaria para que la prueba pase.
-
Refactorizar el código: una vez que pasa la prueba, el desarrollador puede refactorizar el código según sea necesario para mejorar su diseño para mantenerlo, sin cambiar su comportamiento.
Al seguir este proceso, TDD tiene como objetivo producir código de alta calidad que sea correcto y fácil de mantener. TDD también puede ayudar a garantizar que el código cumpla con los requisitos y que los cambios en el código no introduzcan nuevos errores.
Algunas ventajas de TDD incluyen:
-
Calidad de código mejorada: TDD puede ayudar a garantizar que el código sea correcto, confiable y fácil de mantener, lo que puede reducir el costo de desarrollo y mantenimiento con el tiempo.
-
Comentarios más rápidos: al escribir pruebas primero, TDD proporciona comentarios más rápidos al desarrollador, lo que puede ayudar a detectar y corregir errores antes en el proceso de desarrollo.
-
Errores de regresión reducidos: TDD puede ayudar a detectar errores de regresión ejecutando pruebas automáticamente y asegurando que los cambios en el código no rompan la funcionalidad existente.
-
Mejor diseño: al centrarse primero en las pruebas, TDD puede fomentar mejores prácticas de diseño, como acoplamiento flexible, alta cohesión e inyección de dependencia.
Sin embargo, TDD también puede tener algunas desventajas, tales como:
-
Mayor tiempo de desarrollo: escribir pruebas primero puede agregar tiempo adicional al proceso de desarrollo, especialmente si las pruebas son complejas o difíciles de escribir.
-
Dificultad para probar ciertos tipos de código: algunos tipos de código, como las interfaces de usuario o las interacciones de bases de datos, pueden ser difíciles de probar con TDD.
-
Exceso de confianza en las pruebas: TDD puede conducir a una excesiva confianza en las pruebas, que pueden no detectar todos los posibles errores o pueden pasar por alto casos importantes.
20. ¿Qué es JUnit?

JUnit es un popular marco de pruebas Java de código abierto que los desarrolladores utilizan ampliamente para escribir pruebas unitarias para sus aplicaciones Java. Proporciona una manera simple y elegante de escribir pruebas automatizadas, lo que facilita la detección y corrección de errores al principio del ciclo de desarrollo.
JUnit proporciona un conjunto de anotaciones y afirmaciones que se pueden usar para definir y ejecutar pruebas. Algunas de las características clave de JUnit incluyen:
-
Aserciones: JUnit proporciona un conjunto de métodos de aserción que se pueden utilizar para comprobar si una determinada condición es verdadera. Estas aserciones ayudan a verificar que el código bajo prueba se comporta como se esperaba.
-
Anotaciones: JUnit proporciona un conjunto de anotaciones que se pueden usar para definir pruebas, configurar accesorios y controlar el flujo de ejecución de la prueba.
-
Ejecutor de prueba: JUnit proporciona un ejecutor de prueba que se puede usar para realizar pruebas e informar los resultados.
-
Suites de prueba: JUnit permite agrupar las pruebas en suites, que se pueden ejecutar juntas.
JUnit se usa ampliamente en el desarrollo de Java y es compatible con muchos entornos de desarrollo integrados (IDE) como Eclipse, IntelliJ IDEA y NetBeans. Su popularidad y amplia adopción han llevado al desarrollo de muchas herramientas y bibliotecas de terceros que amplían su funcionalidad y la hacen aún más poderosa.
class ExampleServiceTest {
@Mock
private ExampleRepository exampleRepository;
@InjectMocks
private ExampleService exampleService;
@BeforeEach
void setUp() {
MockitoAnnotations.openMocks(this);
}
@Test
void testGetObjectById() {
Long id = 1L;
Example expectedObject = new Example();
when(exampleRepository.findById(id)).thenReturn(expectedObject);
Example result = exampleService.getObjectById(id);
assertEquals(expectedObject, result);
verify(exampleRepository, times(1)).findById(id);
}
@Test
void testCreateObject() {
Example object = new Example();
exampleService.createObject(object);
verify(exampleRepository, times(1)).save(object);
}
@Test
void testUpdateObject() {
Example object = new Example();
exampleService.updateObject(object);
verify(exampleRepository, times(1)).save(object);
}
@Test
void testDeleteObject() {
Long id = 1L;
exampleService.deleteObject(id);
verify(exampleRepository, times(1)).deleteById(id);
}
}
21. ¿Qué es AssertJ?
AssertJ es una biblioteca de Java que proporciona un conjunto de afirmaciones fluidas que facilitan la escritura de pruebas unitarias legibles y expresivas. Está construido sobre JUnit y otros marcos de prueba, proporcionando una manera simple y elegante de escribir aserciones que pueden mejorar la legibilidad y el mantenimiento de sus pruebas.
Algunos ejemplos de afirmaciones AssertJ incluyen:
-
assertThat(): Este es el principal punto de entrada a la biblioteca AssertJ. Toma un valor real y devuelve una instancia del objeto Assert, que se puede usar para encadenar afirmaciones.
-
isEqualTo(): Esta aserción verifica si dos objetos son iguales, utilizando el método equals().
-
isNotNull(): Esta aserción comprueba si un objeto no es nulo.
-
hasSize(): Esta aserción verifica si una colección tiene un tamaño específico.
-
contiene (): esta afirmación verifica si una colección contiene un elemento específico.
Aquí hay un ejemplo de cómo se puede usar AssertJ para escribir una prueba unitaria:
@Test
public void testSum() {
Calculator calculator = new Calculator();
int result = calculator.sum(2, 3);
assertThat(result).isEqualTo(5);
}
En este ejemplo, creamos una instancia de la clase Calculadora y llamamos a su método sum() con dos valores enteros. Luego usamos el método assertThat() para afirmar que el resultado es igual a 5. El método isEqualTo() se usa para verificar si el valor real es igual al valor esperado.
El uso de AssertJ puede ayudar a que sus pruebas sean más legibles y expresivas, lo que facilita la comprensión de la intención de la prueba y el comportamiento esperado del código que se está probando.
Patrones y Principios de diseño
22. Explique el propósito y la aplicación de los patrones de diseño más utilizados: Builder, Factory Method, Abstract Factory, Adapter, Singleton
Los patrones de diseño son soluciones reutilizables para problemas comunes de diseño de software que han demostrado su eficacia a lo largo del tiempo. Aquí hay explicaciones de algunos de los patrones de diseño más utilizados:
-
Builder: este patrón se usa para crear objetos complejos al separar el proceso de construcción del objeto en pasos más pequeños y simples. Proporciona una solución flexible y fácil de usar para crear objetos complejos sin tener que lidiar con constructores complejos o múltiples constructores.
-
Factory Method: este patrón se utiliza para crear objetos sin especificar la clase exacta de objeto que se creará. En su lugar, el método de fábrica crea objetos llamando a un método en un objeto de fábrica que crea el objeto adecuado en función de las entradas proporcionadas.
-
Abstract Factory: este patrón se utiliza para crear familias de objetos relacionados sin especificar las clases exactas de objetos que se crearán. Proporciona una interfaz para crear familias de objetos relacionados, que pueden implementarse mediante varias clases de fábrica concretas.
-
Adapter: este patrón se utiliza para convertir la interfaz de una clase en otra interfaz que esperan los clientes. Es útil cuando la interfaz de una clase existente no coincide con la interfaz que espera un cliente.
-
Singleton: este patrón se utiliza para garantizar que solo se cree una instancia de una clase y que se pueda acceder a ella globalmente a través de una aplicación. Proporciona una forma de centralizar el acceso a una sola instancia de un objeto y, a menudo, se usa en los casos en que es necesario controlar el acceso a los recursos o garantizar la coherencia de los datos.
En general, estos patrones de diseño brindan soluciones útiles a los problemas comunes de diseño de software y pueden ayudar a mejorar la eficiencia, la flexibilidad y la capacidad de mantenimiento de las aplicaciones de software.
23. Explique los siguientes principios de desarrollo de software: DRY, KISS, SOLID
DRY (Don’t Repeat Yourself)
Este principio establece que cada pieza de conocimiento o lógica en un sistema debe tener solo una representación. En otras palabras, aboga por reducir la duplicación de código y promover la reutilización de código. Al adherirse a este principio, los desarrolladores pueden reducir la cantidad de código que necesitan escribir, lo que puede ahorrar tiempo y reducir el riesgo de introducir errores en la base de código.
KISS (Keep It Simple, Stupid)
Este principio aboga por la simplicidad en el diseño de software. Sugiere que el software debe mantenerse simple y fácil de entender, en lugar de ser demasiado complejo. El software simple suele ser más fácil de mantener, probar y depurar, y también puede ser más eficiente que el software complejo.
SOLID
SOLID es un acrónimo que representa cinco principios de diseño de software que se utilizan para promover buenas prácticas de diseño de software.
-
Principio de responsabilidad única (SRP): este principio establece que cada clase debe tener una sola responsabilidad y solo debe ser responsable de una cosa. Esto hace que el código sea más fácil de mantener, probar y modificar, ya que los cambios realizados en una responsabilidad no afectarán a otras responsabilidades.
-
Principio Abierto-Cerrado (OCP): Este principio establece que las entidades de software deben estar abiertas para la extensión pero cerradas para la modificación. En otras palabras, los desarrolladores deberían poder agregar nuevas funciones al sistema sin modificar el código existente. Esto ayuda a promover la reutilización del código y reduce el riesgo de introducir errores en el código existente.
-
Principio de sustitución de Liskov (LSP): este principio establece que los objetos de una superclase deben ser reemplazables con objetos de una subclase sin afectar la corrección del programa. Esto ayuda a garantizar que el código sea más fácil de mantener y se pueda ampliar fácilmente.
-
Principio de segregación de interfaces (ISP): este principio establece que los clientes no deben verse obligados a depender de interfaces que no utilizan. Esto ayuda a mantener el código limpio y simple, y lo hace más fácil de entender y mantener.
-
Principio de Inversión de Dependencia (DIP): Este principio establece que los módulos de alto nivel no deben depender de módulos de bajo nivel, sino que ambos deben depender de abstracciones. Esto ayuda a reducir el acoplamiento entre diferentes partes del sistema, lo que hace que el código sea más flexible y fácil de mantener.
Conocimiento misceláneo
24. Tras el descubrimiento de un error o defecto en una parte del código de producción, ¿Qué criterios puede utilizar para clasificarlo?

Cuando se descubre un error o defecto en el código de producción, se puede clasificar utilizando varios criterios. Algunos criterios comunes que se pueden usar para clasificar los errores son:
-
Gravedad: se refiere a la gravedad del error en términos de su impacto en la aplicación o el sistema. Los errores se pueden clasificar como críticos, mayores, menores o triviales según su gravedad.
-
Prioridad: se refiere a la importancia de corregir el error en relación con otros errores y tareas que deben abordarse. Los errores se pueden clasificar como de prioridad alta, media o baja según su urgencia e impacto.
-
Reproducibilidad: se refiere a la consistencia con la que se puede reproducir el error. Los errores se pueden clasificar como reproducibles o no reproducibles.
-
Causa raíz: Esto se refiere a la razón subyacente del error. Los errores se pueden clasificar según su causa raíz, como error de codificación, falla de diseño o problema ambiental.
-
Área de impacto: se refiere a la parte específica de la aplicación o sistema que se ve afectada por el error. Los errores se pueden clasificar según su área de impacto, como la interfaz de usuario, la base de datos o la red.
-
Frecuencia de ocurrencia: Esto se refiere a la frecuencia con la que ocurre el error. Los errores se pueden clasificar como intermitentes, esporádicos o constantes en función de su frecuencia de aparición.
-
Cobertura de la prueba: se refiere a qué tan bien se cubrió el error en el proceso de prueba. Los errores se pueden clasificar en función de su cobertura de prueba, como perdidos en pruebas unitarias, pruebas de integración o pruebas de regresión.
Al utilizar estos criterios, los desarrolladores y evaluadores pueden priorizar y administrar el proceso de corrección de errores y mejorar la calidad general del producto de software.
25. Explique la semántica RESTful y HTTP
REST (Representational State Transfer) es un estilo arquitectónico para crear servicios web. Se basa en un conjunto de restricciones que enfatizan el uso de protocolos HTTP para acceder y manipular recursos. Los servicios web RESTful proporcionan una interfaz uniforme que permite que diferentes clientes se comuniquen con un servidor a través de Internet.
HTTP (Protocolo de transferencia de hipertexto) es un protocolo utilizado para transferir datos entre un cliente y un servidor a través de Internet. Se basa en un modelo de solicitud-respuesta, donde los clientes envían solicitudes a los servidores y los servidores responden con un mensaje que contiene la información solicitada. HTTP define un conjunto de métodos (también llamados verbos) que se pueden usar para interactuar con los recursos en un servidor.
Los servicios web RESTful utilizan métodos HTTP para interactuar con los recursos. Los métodos HTTP más comunes utilizados en los servicios web RESTful son:
- GET: Se utiliza para recuperar una representación de un recurso.
- POST: Se utiliza para crear un nuevo recurso.
- PUT: Se utiliza para actualizar un recurso existente.
- ELIMINAR: Se utiliza para eliminar un recurso.
Además de los métodos HTTP, los servicios web RESTful también usan URI (identificadores uniformes de recursos) para identificar recursos. Los URI se utilizan para ubicar recursos en el servidor y siguen una estructura jerárquica. Por ejemplo, un URI para un recurso podría ser https://example.com/customers/123.
La semántica HTTP hace referencia al significado y uso de los métodos, encabezados y códigos de estado HTTP. Los métodos HTTP se utilizan para indicar la acción deseada que se realizará en un recurso, mientras que los encabezados HTTP brindan información adicional sobre la solicitud o respuesta. Los códigos de estado HTTP se utilizan para indicar el resultado de una solicitud.
Algunos códigos de estado HTTP comunes incluyen:
- 200 OK: La solicitud fue exitosa.
- 201 Creado: El recurso se creó con éxito.
- 400 Solicitud incorrecta: la solicitud no es válida o tiene un formato incorrecto.
- 401 No autorizado: La solicitud requiere autenticación o autorización.
- 404 No encontrado: No se encontró el recurso solicitado.
- 500 Error interno del servidor: se produjo un error en el servidor.
Comprender la semántica RESTful y HTTP es esencial para crear y consumir servicios web. Permite a los desarrolladores escribir código que sigue las mejores prácticas y es interoperable con otros sistemas.