
Desarrollo basado en contratos 10: El arte de la caché
Posted on January 25, 2024 • 7 minutes • 1458 words • Other languages: English
Usar caffeine para evitar solicitudes innecesarias de API.
Consulta el repositorio de github
Esta es una continuación de Desarrollo basado en contratos 9: El arte de los logs .
Todo lo que haremos aquí, lo puedes encontrar en el repositorio de github.
Spring City Explorer - Backend: Branch feature/cdd-10
¿Qué es el almacenamiento en caché? ¿Por qué es útil en nuestro escenario?
Me dio pereza aquí y pregunté a chatgpt. Aquí está su respuesta
El almacenamiento en caché, en el contexto del desarrollo de software, es una técnica en la que se almacenan copias de datos a los que se accede con frecuencia en un área de almacenamiento temporal, conocida como caché. El objetivo principal es mejorar el rendimiento y la eficiencia de su aplicación. Así es como funciona y por qué es particularmente útil en el escenario que has descrito:
-
Velocidad: Acceder a los datos desde la caché suele ser mucho más rápido que recuperarlos de la fuente original, como una base de datos o una API externa. Cuando se trata de datos meteorológicos, que no cambian cada segundo, almacenar en caché los datos durante una hora significa que las solicitudes posteriores dentro de esa hora se pueden atender casi instantáneamente.
-
Carga reducida: Al almacenar en caché los datos, se reduce la cantidad de solicitudes al servicio meteorológico externo. Esto no solo ayuda a reducir la carga del servicio externo, sino que también minimiza el tráfico de red y puede ahorrar costos, especialmente si el servicio externo cobra por llamada API.
-
Confiabilidad mejorada: Si el servicio meteorológico externo deja de funcionar temporalmente, su aplicación aún puede proporcionar datos desde el caché, lo que garantiza una mejor confiabilidad y experiencia del usuario.
-
Coherencia de los datos: El almacenamiento en caché de los datos meteorológicos durante un período determinado, como una hora, proporciona una vista coherente de los datos a todos los usuarios durante ese período. Esto puede ser particularmente importante en escenarios donde una vista consistente de los datos es más valiosa que la precisión en tiempo real.
Sin embargo, es importante recordar que el almacenamiento en caché es una compensación. Si bien mejora la velocidad y la eficiencia, puede proporcionar datos ligeramente desactualizados. En el caso de la información meteorológica, esta compensación suele ser aceptable ya que las condiciones meteorológicas no cambian drásticamente en períodos cortos. Pero para otros tipos de datos en los que la precisión en tiempo real es fundamental, el almacenamiento en caché puede no ser el mejor enfoque.
Cómo almacenar en caché
1. Agregar dependencias
<!-- Caching Abstraction -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
<version>3.1.2</version>
<scope>compile</scope>
</dependency>
<!-- high performance, near optimal caching library -->
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
<version>3.1.5</version>
<scope>compile</scope>
</dependency>
2. Crear una constante
Este valor será la clave para acceder al caché. Es bueno crear una constante para garantizar la coherencia y evitar el acceso accidental a cachés inexistentes.
Observe cómo también tenemos la clave para acceder a la identificación de la sesión en los registros. Eso lo hicimos en el blog anterior.
public class Constants {
private Constants() {}
public static final String SLF4J_MDC_SESSION_ID_KEY = "sessionId";
public static final String WEATHER_CACHE = "weather";
}
3. Definir cuánto durará la caché
En nuestro caso creo que el clima no cambia mucho en una hora. Así que guardaré el caché durante ese tiempo.
Es una buena práctica agregarlo como propiedad en application.yml. De esa manera:
- Diferentes entornos pueden tener diferentes tiempos de vida de los cachés. Esto puede resultar útil para realizar pruebas cuando no queremos esperar una hora o más para comprobar algún comportamiento.
- Si necesitamos modificar la vida útil, es más fácil editar application.yml y no requiere pruebas exhaustivas.
weather:
baseUrl: http://api.weatherstack.com
secrets:
key: ${WEATHER_API_KEY}
expiresAfter: 3600 #seconds
@Configuration
@ConfigurationProperties(prefix = "weather")
@Data
@FieldDefaults(level = AccessLevel.PRIVATE)
public class WeatherProperties {
String baseUrl;
Map<String, String> secrets;
Integer expiresAfter;
}
4. Crear la configuración de caché
@Configuration
@EnableCaching
@RequiredArgsConstructor
public class CacheConfig {
private final WeatherProperties weatherProperties;
@Bean
public CacheManager cacheManager() {
CaffeineCacheManager caffeineCacheManager = new CaffeineCacheManager(WEATHER_CACHE);
caffeineCacheManager.setCaffeine(
Caffeine.newBuilder()
.expireAfterWrite(weatherProperties.getExpiresAfter(), TimeUnit.SECONDS));
return caffeineCacheManager;
}
}
5. Anotar la función que se desea almacenar en caché
@Service
@RequiredArgsConstructor
public class WeatherServiceImpl implements WeatherService {
private final WeatherApi weatherApi;
private final WeatherProperties weatherProperties;
private final WeatherMapper weatherMapper;
@Override
@Cacheable(value = WEATHER_CACHE)
public Weather getWeatherByCity(String city) {
return weatherMapper.map(
weatherApi.currentGet(
new WeatherApi.CurrentGetQueryParams()
.accessKey(weatherProperties.getSecrets().get("key"))
.query(city)));
}
}
Eso es todo
Agregar un caché es muy sencillo y aporta mucho valor a su aplicación. Además, pareces un desarrollador muy inteligente que sabe lo que está haciendo. Solo hay que tener cuidado de no dispararse en el pie con errores comunes .
¡Ahora probémoslo!
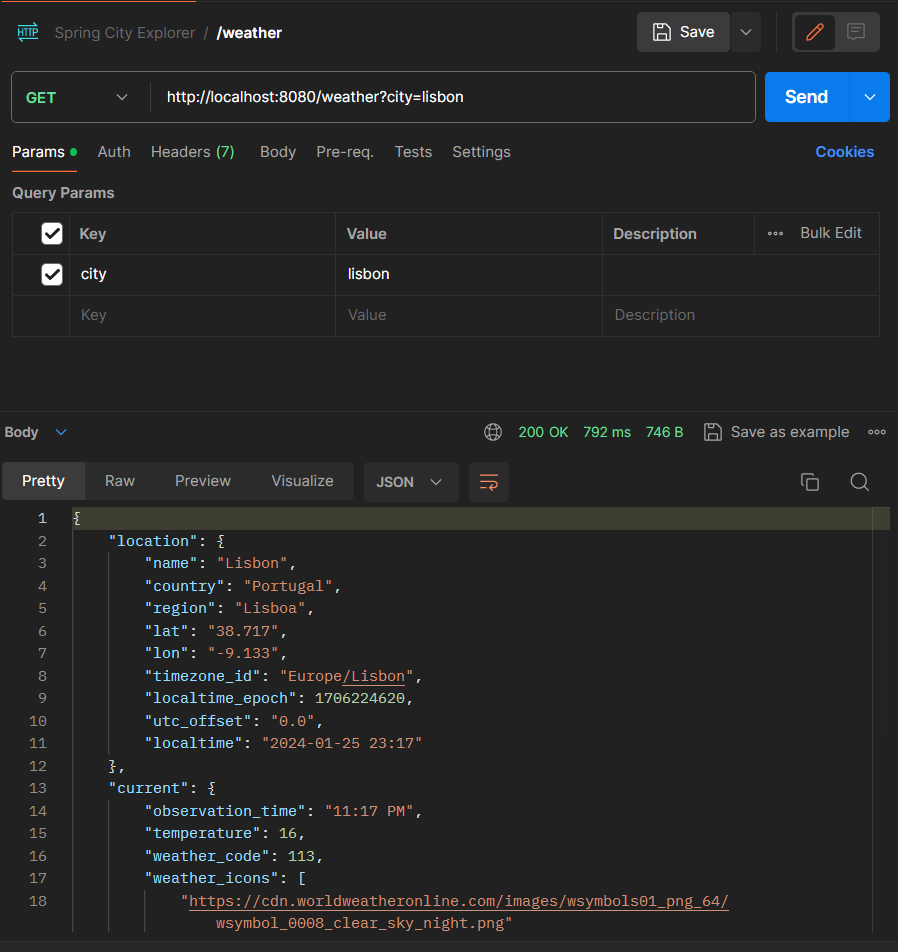
curl --location 'http://localhost:8080/weather?city=lisbon'
Tiempo de solicitud en primera llamada: 792ms
Tiempo de solicitud en las siguientes llamadas: 7ms
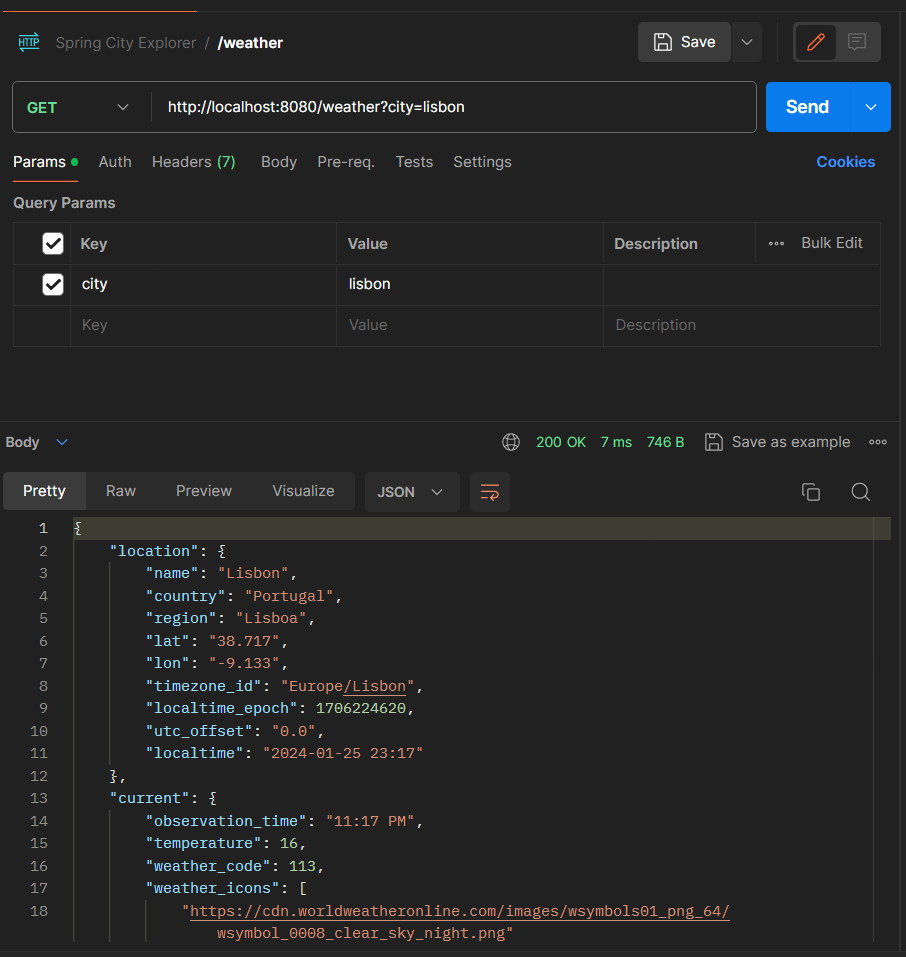
Acabamos de guardar:
- 99,12% del tiempo solicitado
- Solicitudes innecesarias al Weatherstack.api
Algunas notas
Esto funciona al solicitar con otros valores.
- Cuando solicite el clima en Londres, la primera vez será alrededor de 800 ms, y las siguientes solicitudes serán alrededor de 7 ms.
- La solicitud de otras ciudades no afecta la respuesta almacenada en caché para las ciudades anteriores: cada caché tiene su propio tiempo para caducar independientemente de los demás.
Si se lanza una excepción, la caché no guarda nada
En nuestro escenario, cuando solicitamos una ciudad que no existe, se genera una excepción en el nivel del decodificador.
Nuevamente, me volví perezoso y le pedí a chatGPT que explicara los detalles internos de por qué el almacenamiento en caché aquí no funciona.
Dividamos este escenario en términos más simples:
-
El método de servicio genera un error: Cuando su método de servicio encuentra un problema (como una operación fallida de la base de datos o una entrada no válida), genera una excepción. Esto es similar a cuando un chef en un restaurante descubre que un ingrediente se ha echado a perder mientras cocina un plato.
-
El controller advice detecta el error: El controller advice en Spring actúa como un controlador de errores. Es como el gerente de un restaurante que interviene cuando algo sale mal en la cocina. El controller advice intercepta excepciones de toda la aplicación, incluidas las de los métodos de servicio.
-
Por qué no se guarda la caché: El mecanismo de almacenamiento en caché normalmente funciona almacenando el resultado de la ejecución exitosa de un método. Cuando se produce una excepción, el método no se completa exitosamente, por lo que no hay ningún “resultado exitoso” para almacenar en el caché. Es como si el chef no sirviera un plato estropeado a un cliente. El caché solo realiza un seguimiento de los platos (es decir, los resultados del método) que están cocinados adecuadamente y listos para servir.
-
La función del controller advice: El trabajo del controller advice es gestionar el error, no almacenarlo en caché. Decide cuál debe ser la respuesta cuando ocurre un error (como una disculpa del gerente y una oferta de comida gratis la próxima vez). No se preocupa de almacenar el intento fallido de ninguna manera.
En resumen, cuando ocurre un error en la capa de servicio y es detectado por el controller advice, no se guarda ningún caché porque la operación no se completó exitosamente y los mecanismos de almacenamiento en caché están diseñados para almacenar solo los resultados exitosos. ¡Se trata de garantizar que sólo “platos” de calidad lleguen a la “mesa” del caché! 🍽️😊
Nota de Pollito: Cuando estaba en la universidad me hubiera encantado que chatGPT me explicara cosas. Arquitectura del procesador hubiera sido muy fácil.
Próximos pasos
Creo que este es un buen punto de partida, así que dejaré esta serie de blogs aquí por un momento.
Tengo otras cosas en la vida que lograr. Los tres principales son:
- Obtener la certificación Professional Cloud Architect a finales de febrero.
- Tengo una guitarra, todo lo necesario para conectarla a la PC, Musescore
, e incluso un Amplitube 5
con licencia total 100%. En el pasado, solía considerarme un músico. Ahora estoy buscando reconectarme con mi yo interior de músico.

- Quiero un mapa del metro de Lisboa en modo oscuro. Sí, totalmente random y no relacionado, pero soy un nerd de los mapas. El mapa oficial del metro está sobre fondo blanco, lo cual esta ok. Pero lo quiero oscuro para imprimirlo y ponerlo en la pared.
Espero volver a este proyecto. Para cuando regrese, probablemente dejaré este backend como un microservicio que solo obtiene el clima y comenzaré un frontend.
También tengo el sueño de crear el “inicializador Spring Boot 3 de desarrollo basado en contratos de Pollito”. Una página web sencilla donde, dados los archivos yaml que definen tus contratos, genera un proyecto muy opinado con lo que considero buenas prácticas. Prácticamente una imitación de spring intilalizr , pero orientado al desarrollo impulsado por contratos.
Nos vemos en uno o dos meses. Con amor, Pollito 🐤