Spring Cloud: API-Gateway y Naming-Server
Posted on April 9, 2024 • 7 minutes • 1458 words • Other languages: English
[EDIT]: Quité la parte donde me desahogaba sobre mi vida personal que no aportaba al blog.
DISCLAIMER: Esto no es un copy-paste del curso Master Microservices with Spring Boot and Spring Cloud de Udemy. Te recomiendo copadamente comprar ese curso. Yo escribí todo el código que se muestra a continuación.
- ¡Mirá el código!
- ¿Qué es un API-Gateway?
- Ejemplo
- Un vistazo al código de API-Gateway
- Naming-Server
- Algunas consideraciones
- Hagamos que esto funcione
- Próximos pasos
¡Mirá el código!
Podés revisar el código en los siguientes repositorios (en todos, quedate en la rama feature/docker-compose. Puede que veas otras ramas; eso soy yo experimentando con otras soluciones).
¿Qué es un API-Gateway?
Analicemos este diagrama:
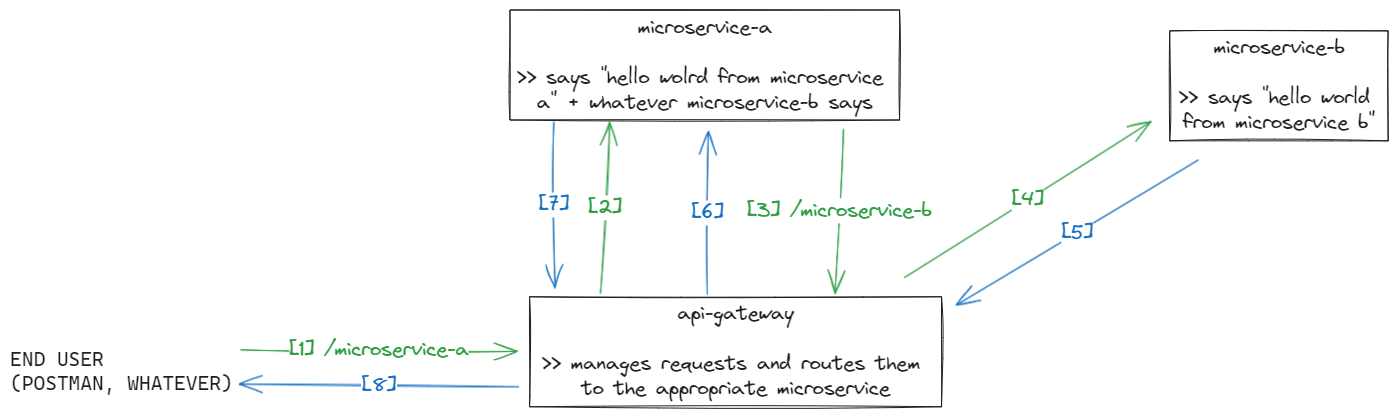
Tenemos:
- Un usuario final: alguien que necesita algo de
microservice-a. microservice-a: devuelve “Hello world from microservice A” + lo que tenga para decirmicroservice-b. O sea, depende demicroservice-b.microservice-b: devuelve “Hello world from microservice B”.
Todo bien hasta acá. Entonces… ¿Qué es eso de “api-gateway”?
Una API Gateway es la puerta principal de tu aplicación, asegurándose de que cada solicitud se dirija al destino correcto. Este gateway cumple varias funciones críticas y se puede aprovechar en distintos casos:
- Routing: El gateway dirige las solicitudes API entrantes al microservicio adecuado, permitiendo que una aplicación cliente haga peticiones usando un único endpoint en lugar de tener que manejar URL para cada servicio.
- Load balancing: Distribuye las solicitudes entrantes de manera uniforme entre las instancias de un microservicio, mejorando así la escalabilidad y confiabilidad del sistema.
- Autenticación y autorización: El gateway puede autenticar las solicitudes entrantes, asegurándose de que provengan de una fuente válida, y opcionalmente imponer controles de acceso, decidiendo a qué servicios puede acceder una solicitud válida.
- Rate limiting: Para evitar que un solo servicio se sature, el gateway puede limitar la cantidad de peticiones que se hacen a un servicio en un determinado período.
- Cross-Cutting concerns: Puede encargarse de otros aspectos como el registro de logs, monitoreo y seguridad en todos los servicios sin que haya que duplicar esfuerzos en cada microservicio.
- Aggregation: El gateway puede agregar resultados de múltiples microservicios y retornar una respuesta consolidada al cliente, reduciendo la cantidad de idas y vueltas entre el cliente y el servidor.
Casos de uso:
- Aplicaciones de comercio electrónico: En un sistema de e-commerce, el gateway puede dirigir las solicitudes de búsqueda de productos al servicio de productos, la gestión del carrito al servicio de carrito y el procesamiento de pedidos al servicio de órdenes, ofreciendo una experiencia de compra fluida.
- Aplicaciones de IoT: En plataformas de Internet de las Cosas, el gateway puede manejar solicitudes de millones de dispositivos, encaminándolas a los servicios adecuados para procesamiento de datos, administración de dispositivos y analíticas.
- Aplicaciones móviles: Los backends móviles pueden aprovechar los API Gateways para simplificar la comunicación del lado del cliente, gestionar diferentes versiones de backend y agregar datos de múltiples fuentes.
Al actuar como punto central para gestionar y dirigir el tráfico, un microservicio gateway mejora el mantenimiento, escalabilidad y seguridad de las aplicaciones en la nube.
Ejemplo
Analicemos el diagrama, otra vez, pero con más foco en cada paso.
- Alguien llama a
api-gateway/microservice-a. Elapi-gatewayrecibe la solicitud y hace lo que esté programado para hacer con ella (podría, quizás, agregar un header, chequear la autenticación, codificar/decodificar info, o simplemente ser transparente y no hacer nada). - El
api-gatewaysabe dónde estámicroservice-ay reenvía la solicitud. microservice-arecibe la solicitud. Necesita algo demicroservice-b, así que hace una nueva solicitud que pasa por el gateway.- Nuevamente, el
api-gatewayhace lo que esté programado para hacer con esta nueva solicitud amicroservice-b. Sabe dónde estámicroservice-by la reenvía. microservice-brecibe la solicitud, la procesa y responde.- El
api-gatewayretorna (o reenvía la respuesta). microservice-aprocesa la respuesta demicroservice-by responde.- Respuesta final.
¿Podrías haber ahorrado algunas solicitudes/respuestas pasando directamente de microservice-a a microservice-b? Sí, totalmente. Pero solo por motivos de ejemplo, decidí hacerlo de esta manera. Quizás en tu caso necesites ahorrar esas solicitudes extra, o tal vez siempre deban pasar por el gateway. Cada realidad es distinta.
Un vistazo al código de API-Gateway
Al mirar el código del api-gateway, te das cuenta de algo… ¡Está bastante vacío!
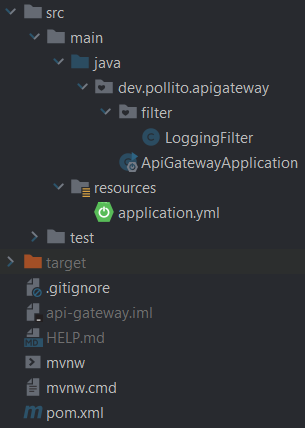
- El LoggingFilter es simplemente un filtro que registra todo lo que pasa. En este ejemplo, no altero nada de la solicitud entrante ni realizo comprobaciones según de dónde viene o a dónde va. Acá es donde podés ser creativo.
- El archivo principal de la aplicación es simplemente el main por defecto de Spring Boot, vacío.
¿Cómo sabe el api-gateway a dónde enviar las solicitudes? La respuesta está en el pom.xml.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>
La dependencia de spring-cloud-starter-gateway le confiere al microservicio todas las características de un gateway.
Acá, la gran protagonista es spring-cloud-starter-netflix-eureka-client. Registra tu API Gateway como un cliente en el Eureka Server (un registro de servicios). Esto permite al gateway descubrir y hacer seguimiento de las instancias de microservicios disponibles en tu ecosistema.
Cuando llega una solicitud al API Gateway, ocurren los siguientes pasos:
- El gateway identifica la ruta y el microservicio al que se debe reenviar la solicitud según las reglas de enrutamiento configuradas.
- El gateway consulta al Eureka Server para obtener las instancias actuales del microservicio objetivo, incluyendo sus ubicaciones de red.
- El Eureka Server responde con la información sobre las instancias disponibles. Puede devolver múltiples instancias si el microservicio objetivo está escalado horizontalmente para alta disponibilidad.
- El gateway aplica cualquier estrategia de balanceo de carga configurada para seleccionar una instancia si hay varias disponibles.
- La solicitud se reenvía a la instancia de microservicio elegida para su manejo.
Esta combinación de Spring Cloud Gateway y Eureka Client permite el enrutamiento dinámico basado en el descubrimiento de servicios, haciendo el sistema más resiliente y escalable.
La API Gateway no necesita estar configurado de forma estática con las ubicaciones de los microservicios. En cambio, los resuelve de forma dinámica, acomodando cambios en tiempo real en el panorama de microservicios, como eventos de escalado o servicios que se caen por mantenimiento.
Naming-Server
El Eureka Client registra los microservicios en un registro de servicios. Ahora necesitamos ese registro. Yo lo llamo naming-server.
Cuando mirás su código, te das cuenta de algo… ¡Está literalmente vacío! Solo tiene la clase principal de Spring Boot con una anotación.
@SpringBootApplication
@EnableEurekaServer
public class NamingServerApplication {
public static void main(String[] args) {
SpringApplication.run(NamingServerApplication.class, args);
}
}
Nuevamente, toda la magia la hace una dependencia en el archivo pom.xml.
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>
Algunas consideraciones
Registrándose en Naming-Server
Cada microservicio que quiera registrarse en el naming-server para ser encontrado por otros microservicios necesita:
- Dependencias actuator + eureka client:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
<version>3.2.4</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
<version>4.1.1</version>
</dependency>
- Este fragmento de código en su
application.yml:
eureka:
client:
serviceUrl:
defaultZone: http://localhost:8761/eureka # o la dirección donde esté el eureka server
instance:
prefer-ip-address: true
¿Qué son esas dependencias de Micrometer y Zipkin?
El curso Master Microservices with Spring Boot and Spring Cloud de Udemy también incluye contenido sobre logging y tracing, así que decidí implementarlos acá también.
Sin entrar en demasiadas tecnicidades, esas dependencias ayudan a:
- Asignar IDs únicos a los logs.
- Transmitir esos ID a través de los microservicios, para poder trazar por dónde pasó la solicitud inicial.
- Mostrar en un dashboard las trazas y métricas.
Lo único que tuvo que cambiar en el código de negocio para que estas dependencias funcionen fue:
- Agregar algunas capacidades al construir el cliente Feign. Acá un ejemplo tomado de
microservice-a:
@Configuration
@ComponentScans(
value = {
@ComponentScan(
basePackages = {
"dev.pollito.microserviceb.api",
})
})
@RequiredArgsConstructor
public class MicroserviceBApiConfig {
private final MicroserviceBProperties microserviceBProperties;
private final MeterRegistry meterRegistry;
private final ObservationRegistry observationRegistry;
@Bean
public HelloWorldApi microServiceBApi() {
return Feign.builder()
.client(new OkHttpClient())
.encoder(new GsonEncoder())
.decoder(new GsonDecoder())
.errorDecoder(new MicroserviceBErrorDecoder())
.logger(new Slf4jLogger(HelloWorldApi.class))
.logLevel(Logger.Level.FULL)
.addCapability(new MicrometerObservationCapability(observationRegistry)) // <-- ESTO ES NUEVO
.addCapability(new MicrometerCapability(meterRegistry)) // <-- ESTO ES NUEVO
.target(HelloWorldApi.class, microserviceBProperties.getBaseUrl());
}
}
- Agregar algunas configuraciones en el
application.yml:
logging:
pattern:
level: "%5p [${spring.application.name:},%X{traceId:-},%X{spanId:-}]"
management:
tracing:
sampling:
probability: 1.0
Hagamos que esto funcione
Usá el archivo docker-compose para arrancar todo. No voy a entrar en detalles de cómo funciona docker-compose. Este es un blog de Spring Cloud, no de Docker.
Personalmente, me gusta usar Docker Desktop para estas cosas, pero podés hacerlo desde CMD.
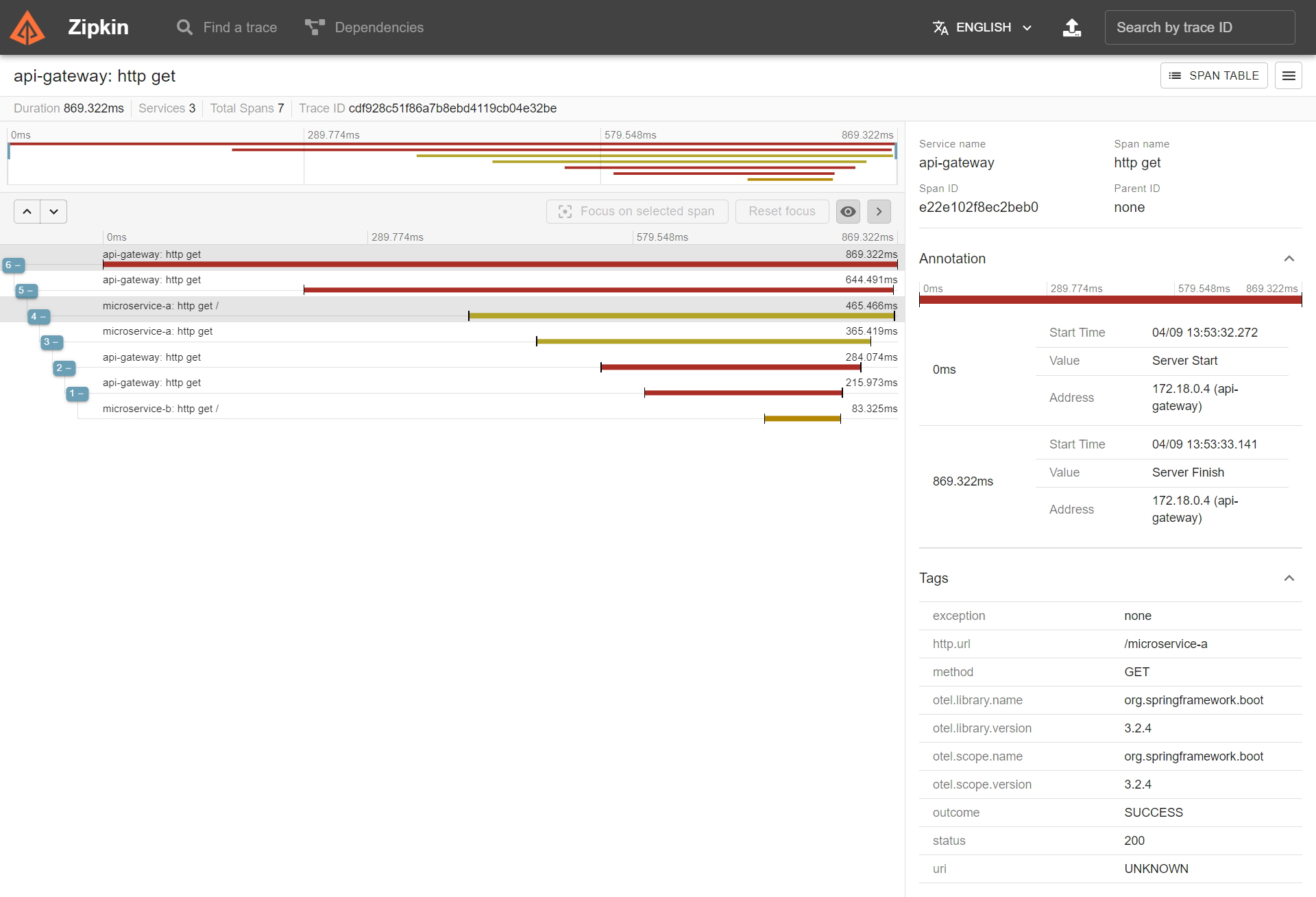
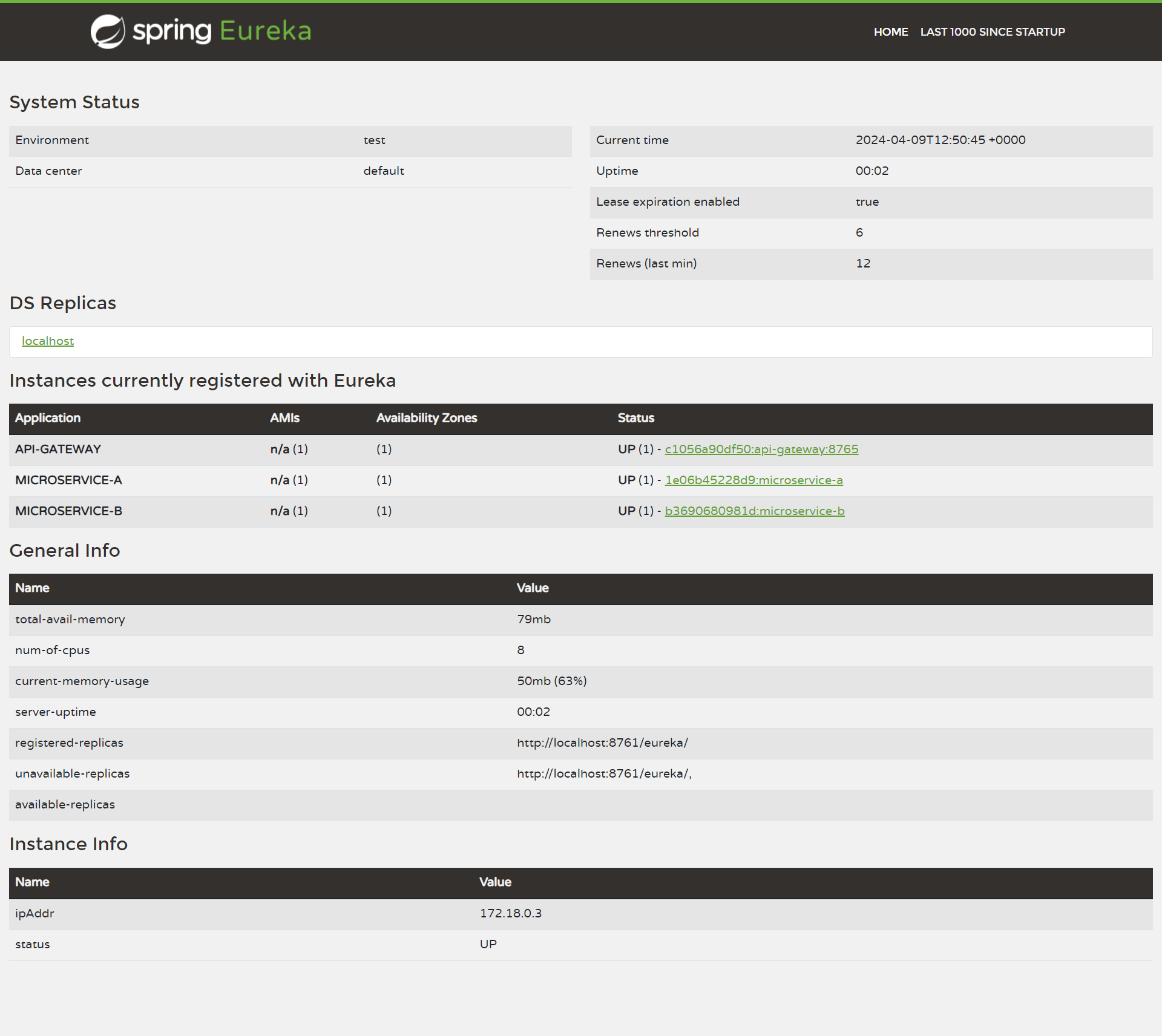
Si entrás a localhost:8761 , vas a encontrar el Eureka Server con todos los servicios que se registraron.
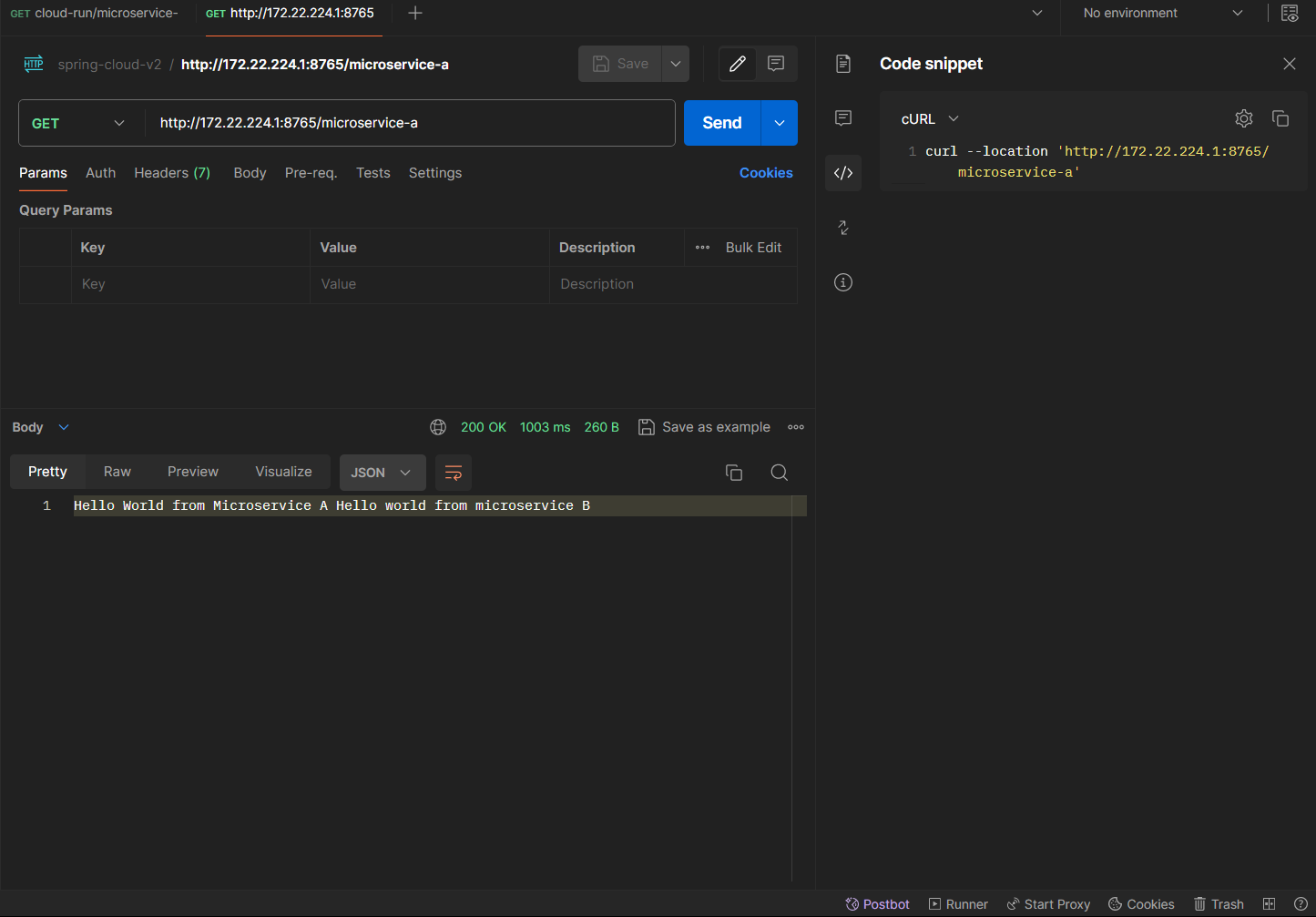
Ejecutar este curl hará todo el proceso de pasar por el api-gateway, microservice-a, microservice-b y regresar.
curl --location 'http://172.22.224.1:8765/microservice-a'
Podés ver cómo la solicitud recorre todos los microservicios gracias a Zipkin. Entrá a http://localhost:9411/zipkin/ .
Hacé clic en “RUN QUERY” y vas a ver tu solicitud.
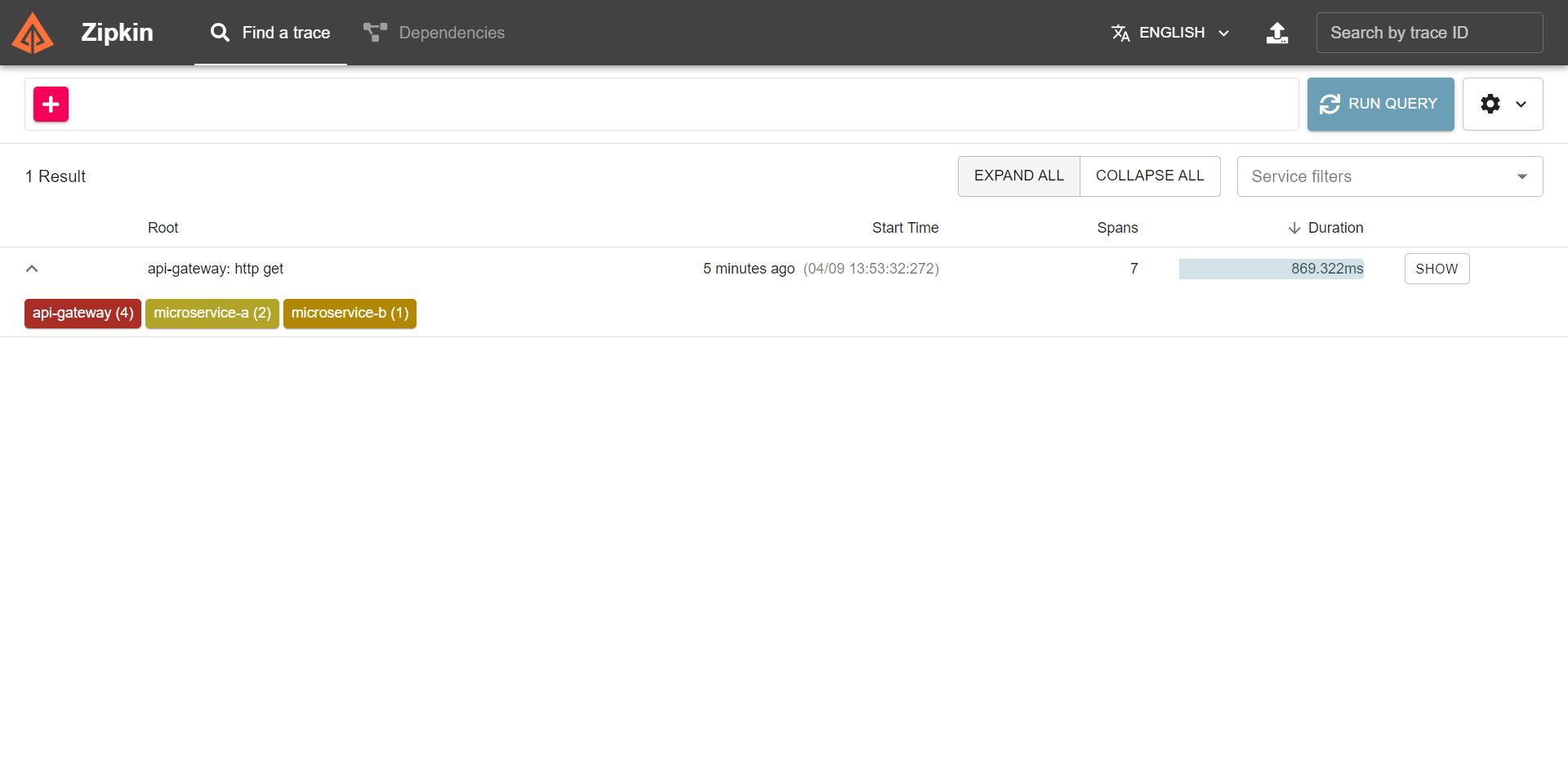
Hacé clic en “SHOW” para ver más detalles.