
Large Software Projects: Panel de Control de Monitoreo
Posted on November 2, 2025 • 8 minutes • 1629 words • Other languages: English
Este post es parte de mi serie de blogs sobre Proyectos de Software Grandes .
- Código Fuente
- Dependencias
- El Ambiente de Ejecución de Node.js
- Instrumentación de Next.js
- Configuración de Variables de Entorno
- /api/metrics
- Demostración del Logger
- Montaje del Stack de Monitoreo
- Configuración del Dashboard de Grafana
- Solucionando la Pantalla en Blanco
- ¿Qué Sigue?
Código Fuente
Todos los snippets de código que aparecen en este post están disponibles en la rama dedicada a este artículo en el repo de GitHub del proyecto:
https://github.com/franBec/tas/tree/feature/2025-11-02
Dependencias
Necesitamos instalar estos paquetes:
prom-client: Librería para generar métricas en formato Prometheus. Con solo llamar a una función simple, obtenemos insights automáticos sobre CPU, memoria y recolección de basura; data que, a veces, es un quilombo recolectar solo con métodos de OpenTelemetry puros.pino: Un logger JavaScript de muy bajo overhead.pino-loki: La capa de transporte que toma los logs formateados y los manda directamente a nuestra instancia de Loki que esté corriendo.@vercel/otel: La librería oficial de distribución OpenTelemetry de Vercel para Next.js, haciendo que el tracing y la creación de spans sea simple dentro del framework.@opentelemetry/sdk-logs/@opentelemetry/api-logs/@opentelemetry/instrumentation: Los componentes fundamentales de OpenTelemetry que necesitamos para armar un ecosistema de tracing y logging como corresponde.
Para instalarlos, ejecutá:
pnpm add prom-client pino pino-loki @vercel/otel @opentelemetry/sdk-logs @opentelemetry/api-logs @opentelemetry/instrumentation
El Ambiente de Ejecución de Node.js
Algo clave a tener en cuenta en Next.js es que hay partes de tu aplicación que corren en ambientes distintos.
- Node.js Runtime: El entorno de servidor tradicional, con todas las funciones. Acá es donde deben correr las herramientas de monitoreo a nivel de sistema, como
prom-client. - Edge Runtime: Un entorno súper liviano optimizado para la velocidad de red. No soporta todas las APIs de Node.js.
Por eso, en varios snippets de código vas a ver chequeos explícitos del entorno nodejs para evitar que se nos rompa todo al importar e inicializar las herramientas de monitoreo.
Instrumentación de Next.js
Next.js usa un archivo especial llamado src/instrumentation.ts para ejecutar código de inicialización una sola vez cuando se inicia una nueva instancia del servidor. Este es el lugar ideal para dejar registrado nuestro sistema de métricas.
Vamos a hacer lo siguiente:
- Inicializar el registro de métricas y dejarlo disponible globalmente usando
globalThis.metrics. - Inicializar el logger y dejarlo disponible globalmente usando
globalThis.logger.- Habilitar la Correlación de Trace a Logs.
- Registrar OpenTelemetry.
declare global {
var metrics:
| {
registry: any;
}
| undefined;
var logger: any | undefined;
}
export async function register() {
if (process.env.NEXT_RUNTIME === "nodejs") {
const { Registry, collectDefaultMetrics } = await import("prom-client");
const pino = (await import("pino")).default;
const pinoLoki = (await import("pino-loki")).default;
const { registerOTel } = await import("@vercel/otel");
//prom-client initialization
const prometheusRegistry = new Registry();
collectDefaultMetrics({
register: prometheusRegistry,
});
globalThis.metrics = {
registry: prometheusRegistry,
};
//loki initialization
globalThis.logger = pino(
{
mixin() {
const { trace } = require("@opentelemetry/api");
const span = trace.getActiveSpan();
if (span) {
const context = span.spanContext();
return {
trace_id: context.traceId,
span_id: context.spanId,
trace_flags: context.traceFlags,
};
}
return {};
},
},
pinoLoki({
host: process.env.LOKI_HOST || "http://localhost:3100",
batching: true,
interval: 5,
labels: {
app: process.env.OTEL_SERVICE_NAME || "next-app",
environment: process.env.NODE_ENV || "development",
},
})
);
//OTel registration
registerOTel();
}
}
- Excepción de Linting: Como tuvimos que usar las declaraciones
globalThis, este archivo va a chocar con las reglas de linting. Agregásrc/instrumentation.tsa la lista de ignorados eneslint.config.mjs. - Excepción de Testing: Como es un archivo de infraestructura, no tiene sentido hacerle testing unitario. Agregá
src/instrumentation.tsa la lista de exclusión de cobertura de pruebas envitest.config.mts.
Configuración de Variables de Entorno
Para que Loki y OTel sepan dónde mandar la data y cómo etiquetarla, necesitamos configurar variables de entorno específicas.
-
Configuración de Ejecución/Debug del IDE: Si usás un IDE tipo JetBrains WebStorm , podés agregar estas variables directamente a las opciones de configuración de Run/Debug:
Seteá la siguiente cadena de entorno:
LOKI_HOST=http://localhost:3100;OTEL_EXPORTER_OTLP_ENDPOINT=http://localhost:4318;OTEL_LOG_LEVEL=info;OTEL_SERVICE_NAME=next-app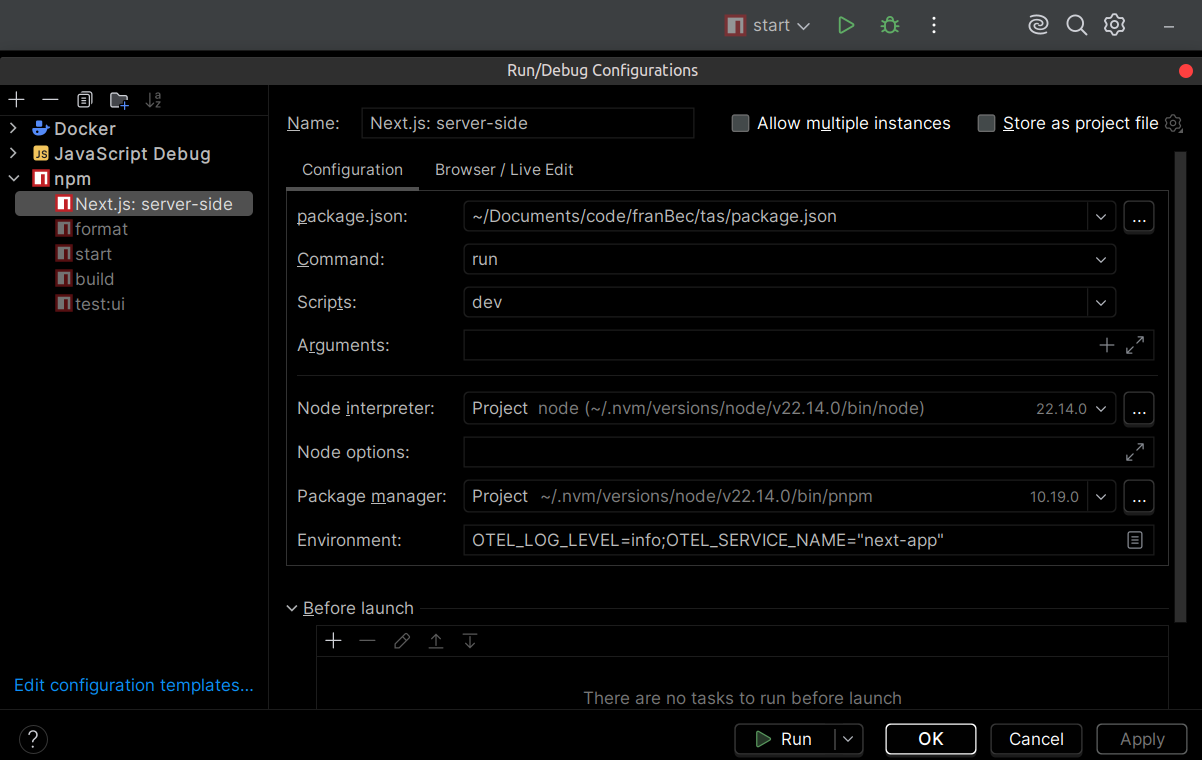
Tip: Recomiendo guardar todas tus variables de entorno de desarrollo (las que no son sensibles) en un archivo de texto (ej.
src/resources/env-dev.txt), así los desarrolladores nuevos simplemente copian y pegan en su configuración del IDE. -
Archivo
.envdel Proyecto: Usamos el archivo.envdel proyecto para referenciar estas variables de entorno, haciéndolas disponibles para el proceso de build y el runtime de Next.js.# OTel Configuration OTEL_LOG_LEVEL="${OTEL_LOG_LEVEL}" OTEL_SERVICE_NAME="${OTEL_SERVICE_NAME}" OTEL_EXPORTER_OTLP_ENDPOINT="${OTEL_EXPORTER_OTLP_ENDPOINT}" # Loki Configuration LOKI_HOST="${LOKI_HOST}"
/api/metrics
Prometheus usa el sistema “pull”: no espera a que tu aplicación le mande datos; periódicamente hace un “scrape” de la data desde un endpoint HTTP dedicado que vos exponés.
Creamos una ruta API simple en api/metrics que usa nuestro registro definido globalmente para exponer los datos de las métricas.
import { NextResponse } from "next/server";
export const runtime = "nodejs";
export async function GET() {
try {
if (!globalThis?.metrics?.registry) {
return new NextResponse("Metrics Unavailable", {
status: 503,
headers: {
"Content-Type": "text/plain",
},
});
}
const metrics = await globalThis.metrics.registry.metrics();
return new NextResponse(metrics, {
headers: {
"Content-Type": "text/plain",
},
});
} catch (error) {
console.error("Error collecting metrics:", error);
return new NextResponse("Error collecting metrics", {
status: 500,
headers: {
"Content-Type": "text/plain",
},
});
}
}
Demostración del Logger
Ahora que el logger está inicializado globalmente, hagamos dos rutas API sencillas para demostrar el logueo exitoso y el logueo de errores. Nos aseguramos de que estas rutas usen explícitamente el runtime nodejs para garantizar que tengan acceso a la configuración de instrumentación.
Vamos a definir /api/hello-world (siempre 200) y /api/something-is-wrong (siempre 500).
/api/hello-world
export const runtime = "nodejs";
export async function GET() {
try {
const { randomUUID } = await import("crypto");
globalThis?.logger?.info({
meta: {
requestId: randomUUID(),
extra: "This is some extra information that you can add to the meta",
anything: "anything",
},
message: "Successful request handled",
});
return Response.json({
message: "Hello world",
});
} catch (error) {
globalThis?.logger?.error({
err: error,
message: "Something went wrong during success logging",
});
}
}
/api/something-is-wrong
export const runtime = "nodejs";
export async function GET() {
try {
throw new Error("Something is fundamentally wrong with this API endpoint");
} catch (error) {
globalThis?.logger?.error({
err: error,
message: "An error message here",
});
return new Response(JSON.stringify({ error: "Internal Server Error" }), {
status: 500,
});
}
}
Montaje del Stack de Monitoreo
Vamos a definir dos archivos docker-compose.yml:
- src/resources/monitoring.yml (Producción – Coolify): Define los servicios y la configuración con variables de entorno adecuadas para el deployment vía Coolify.
- src/resources/monitoring-dev.yml (Desarrollo Local): Puertos expuestos para debugging.
Cada archivo monitoring*.yml es demasiado largo para analizarlo acá en detalle (+200 líneas), pero en esencia describen cómo Docker debe crear y conectar todo el entorno de monitoreo.
| Aspecto | Desarrollo | Producción |
|---|---|---|
| Red (Network) | monitoring (bridge) |
coolify (external) |
| Ubicación de Next.js | Corre en la máquina host | Corre dentro de Docker |
| Target de Next.js | host.docker.internal:3000 |
next-app:3000 |
| Host de Loki (desde Next.js) | http://localhost:3100 |
http://loki:3100 |
| Endpoint de OTEL | http://localhost:4317 |
http://otel-collector:4317 |
| Usuario de Tempo | root (atajo de permisos) |
Usuario por defecto (seguro) |
| Puertos Expuestos | Todos (debugging) | Mínimos (seguridad) |
Configuración del Dashboard de Grafana
Asegurate de que tu motor Docker (como Docker Desktop ) esté corriendo de fondo.
- Iniciá el Stack:
docker compose -f src/resources/monitoring-dev.yml up - Iniciá la App: Corré el script de inicio de tu aplicación Next.js en tu máquina host.
Andá a http://localhost:3001
e iniciá sesión usando las credenciales definidas en el monitoring-dev.yml (admin_user/admin_password).
Importar un Dashboard
- Andá a Import dashboard
. Subí un archivo JSON de dashboard que ya preparé
.
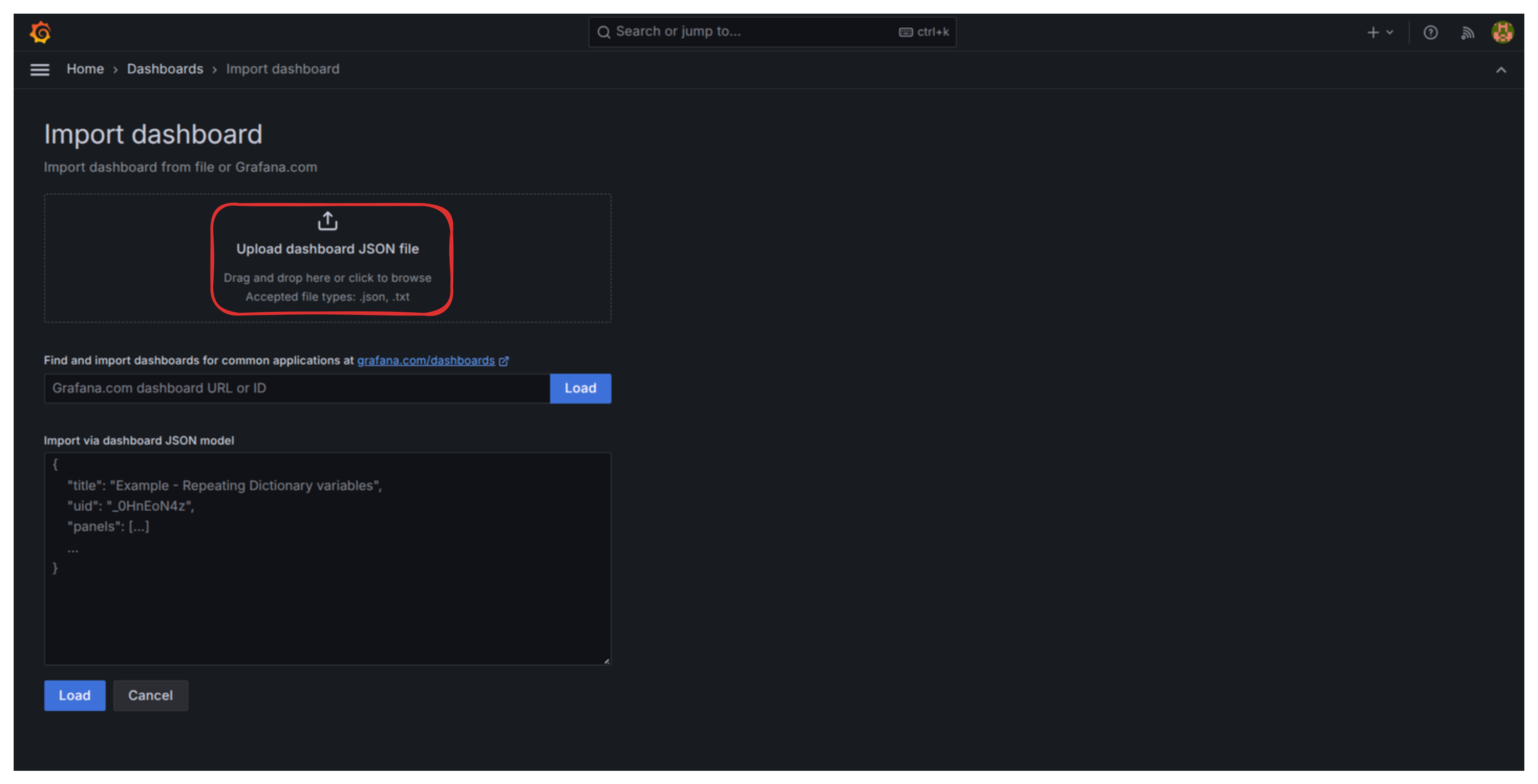
- Cuando te pida la fuente de datos (datasource) de Loki y Prometheus, simplemente seleccionalas y hacé clic en “Importar”.

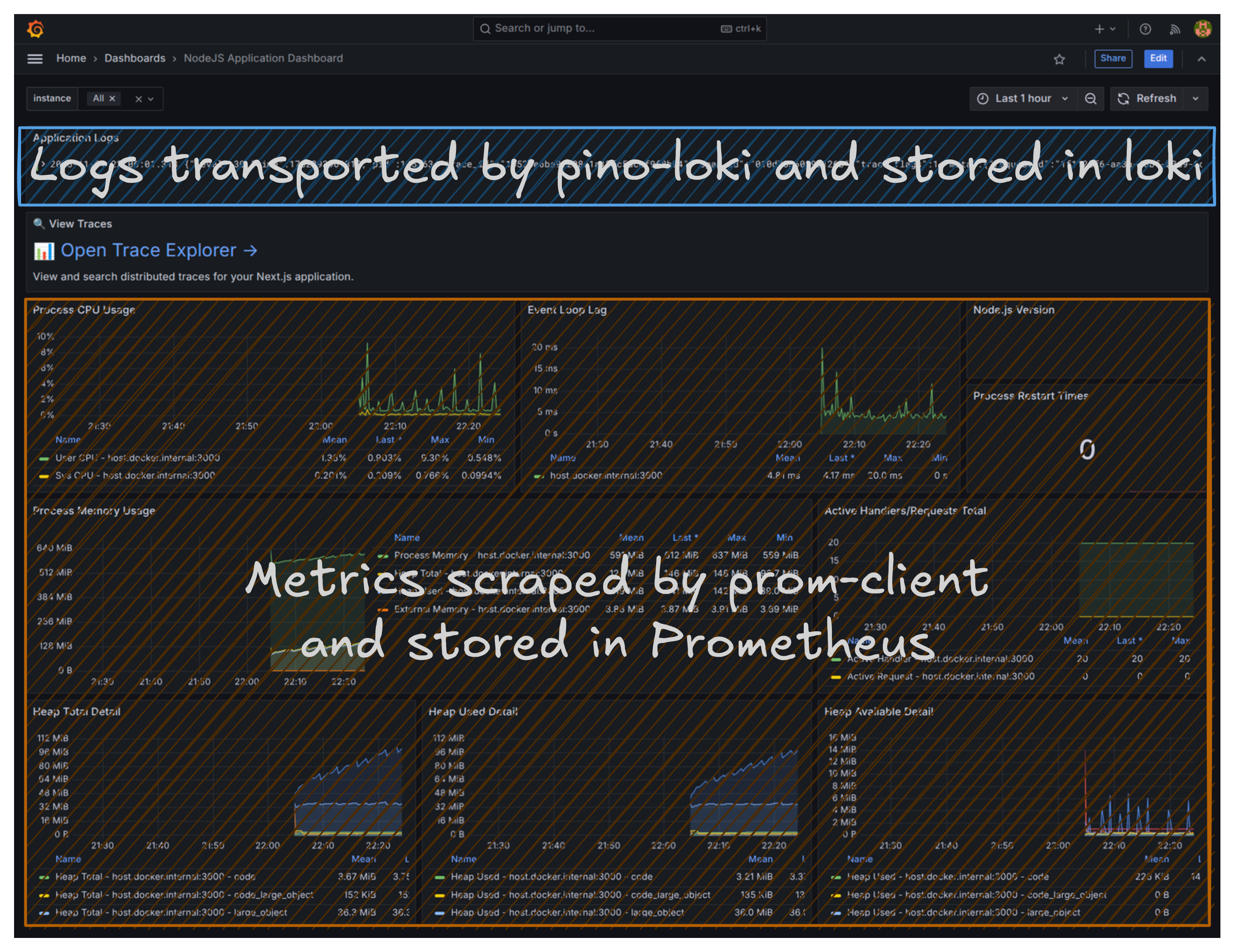
¡Listo! Ahora tenés un dashboard de monitoreo unificado mostrando métricas (como uso de CPU, consumo de memoria, actividad de recolección de basura, conteo de peticiones), logs de la aplicación y un link al Trace Explorer.
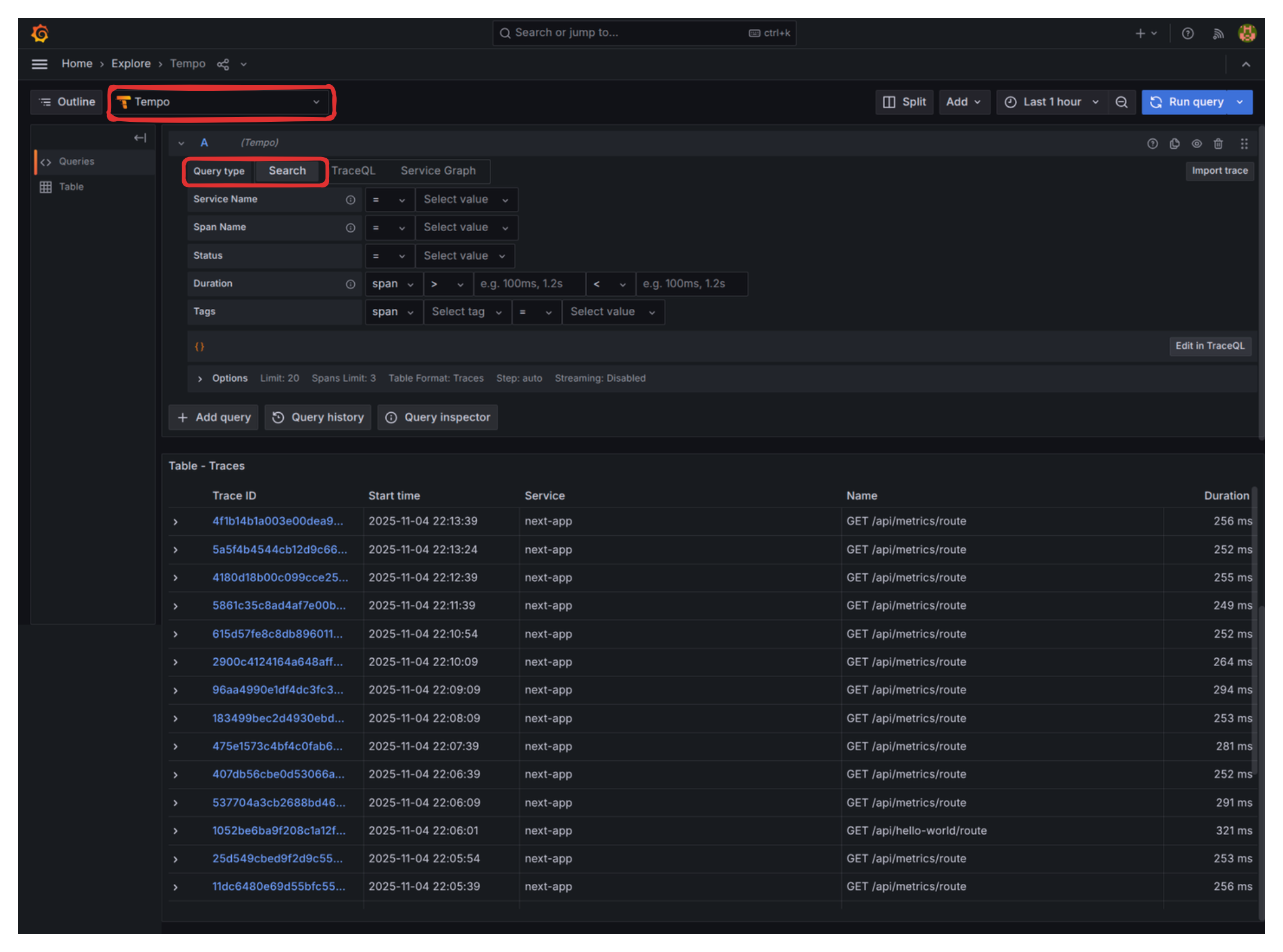
- Visitá un par de veces a las rutas
/api/hello-worldy/api/something-is-wrongpara generar data. - Cuando revises el “Trace Explorer”, asegurate de tener “Tempo” como la fuente de datos seleccionada y “Search” como el tipo de consulta.
Solucionando el Panel de Grafana: Arreglando la Versión de Node.js
Un pequeño problema con este dashboard es que el panel de “Node.js version” aparece vacío. Arreglemos esto:
- Hacé clic en los tres puntos verticales en la esquina superior derecha de ese panel vacío y seleccioná Edit.

- En el editor de Query (área “Metric browser”), borrá la consulta por defecto e ingresá el nombre de la métrica correcta:
nodejs_version_info. - En el panel de la derecha, en “Value options” -> “Calculation” seteá
Last *. - Debajo, en “Value options” -> “Fields” ya deberías poder seleccionar la cadena de la versión.
- Hacé clic en “Run queries” para confirmar que aparece la data.
- Hacé clic en el botón “Save Dashboard” (arriba a la derecha).
Solucionando la Pantalla en Blanco
Volvamos al problema que tuvimos en Proyectos de Software Grandes: Introducción al Monitoreo : la pantalla en blanco en producción. Vamos a recrear el escenario con un componente que se rompe a propósito.
Creá una ruta simple /route-with-error con lógica rota:
export const dynamic = "force-dynamic";
async function getData() {
const res = await fetch("https://httpbin.org/status/500");
return res.json();
}
export default async function RouteWithError() {
const data = await getData();
return (
<div className="flex flex-col gap-4">
<p>
The data is: <strong>{JSON.stringify(data)}</strong>
</p>
</div>
);
}
Si visitás http://localhost:3000/route-with-error en un build de producción, vas a obtener la temida página en blanco sin ninguna indicación de lo que pasó.
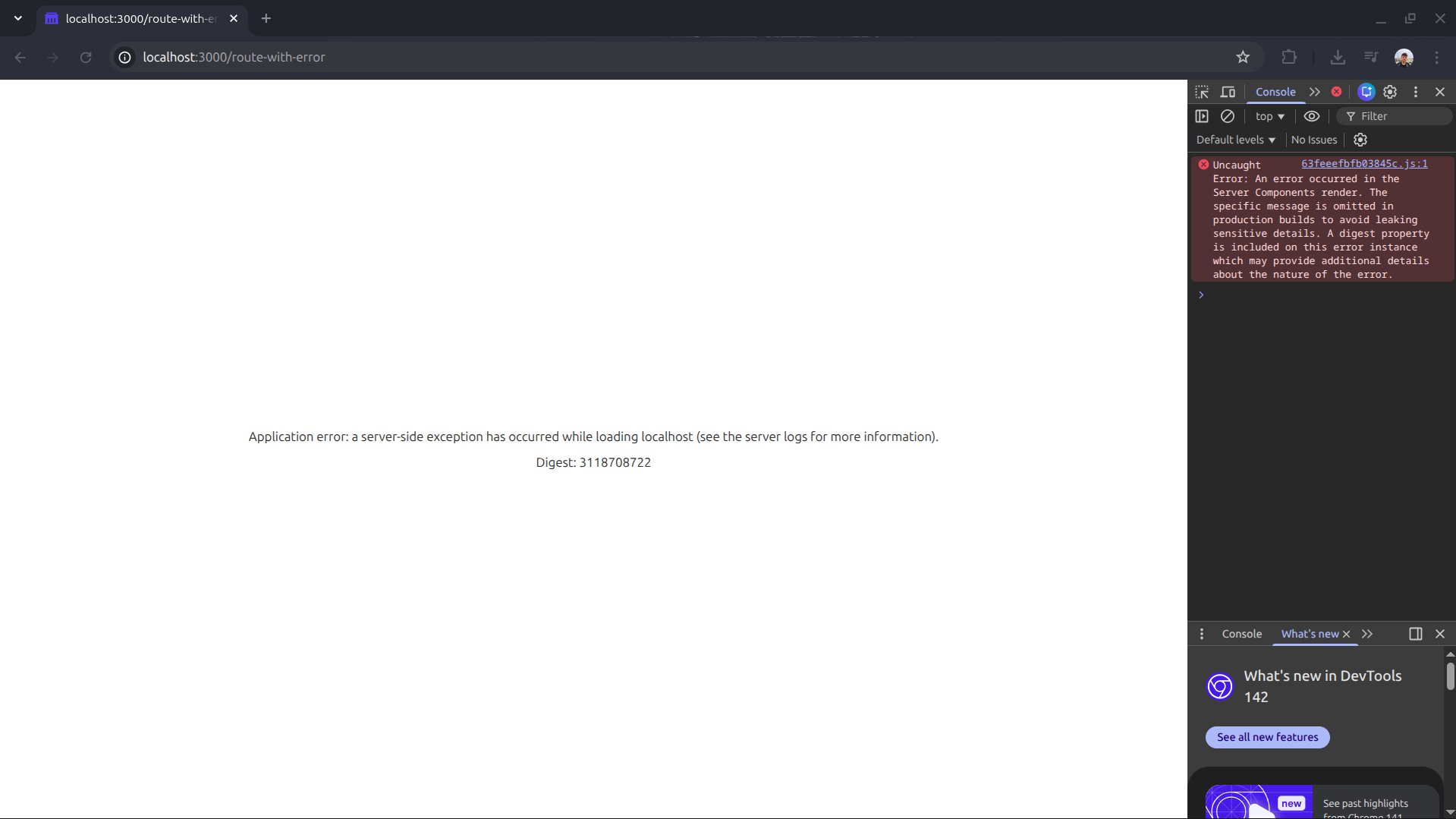
Sin embargo, cuando chequeamos el “Trace Explorer” y filtramos por Status “Error”, la historia es completamente otra:
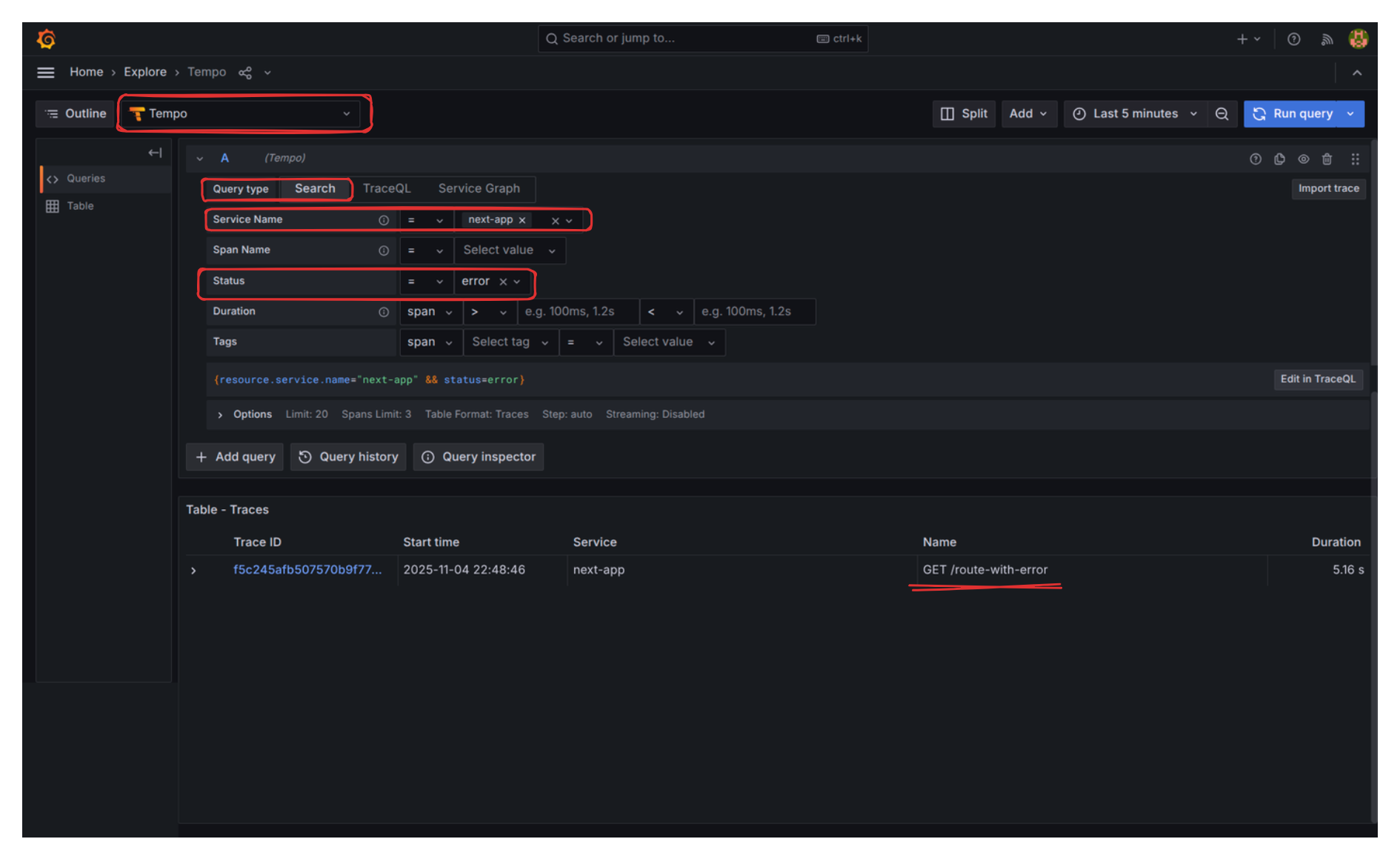
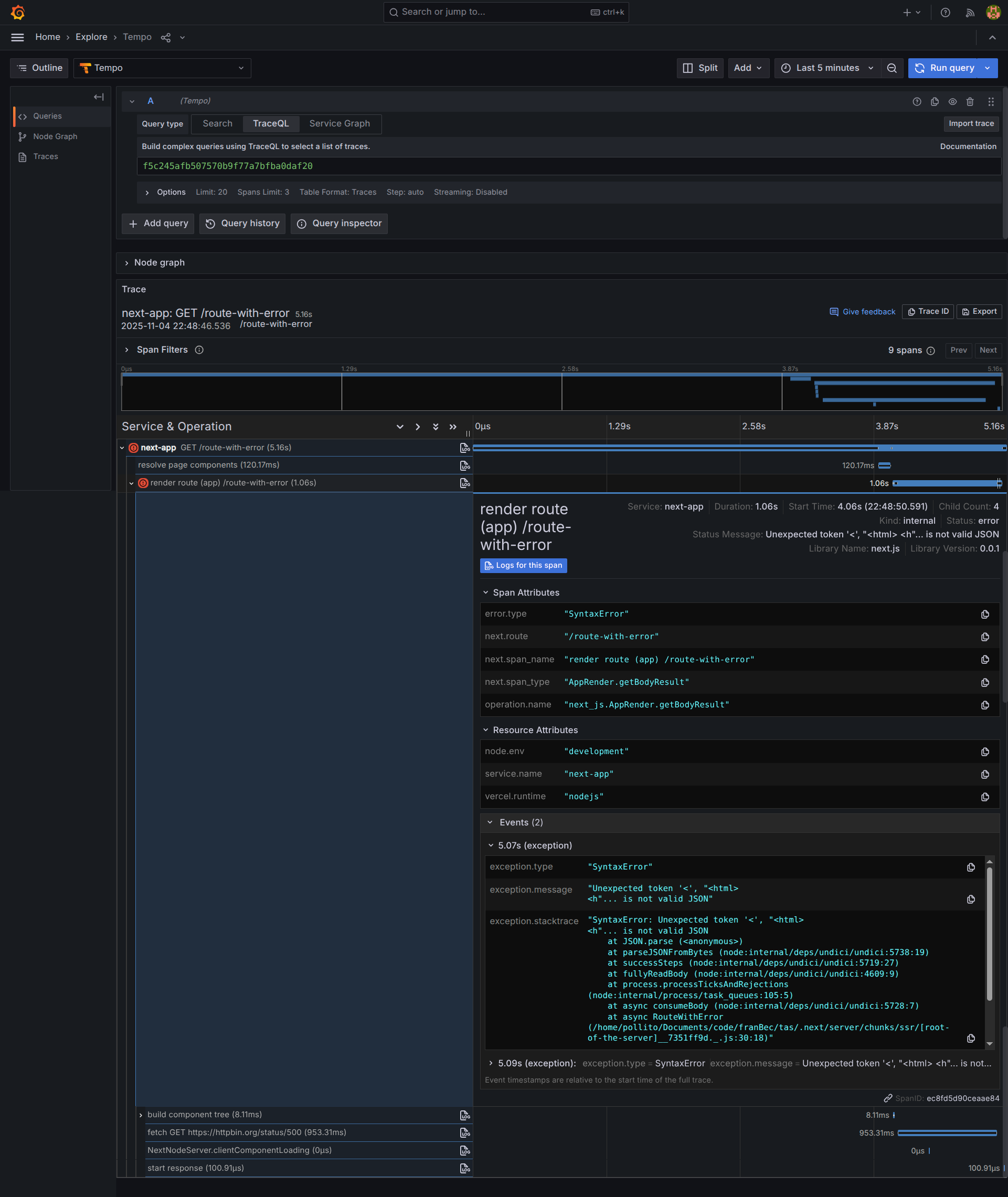
Si hacemos clic en el trace, encontramos los detalles exactos:
¿Qué Sigue?
Ya establecimos un stack de monitoreo local y robusto, usando herramientas estándar de la industria.
El siguiente paso obvio es llevar esta misma estrategia de monitoreo a nuestro ambiente de producción en el VPS, lidiando con los desafíos de los hostnames externos, el almacenamiento persistente y la autenticación.
Próximo Blog: Proyectos de Software Grandes: Monitoreando tu App en Producción